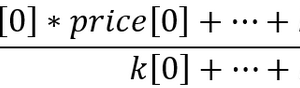概述
在之面的文章(优化管理(第一部分)和优化管理(第二部分))当中,我们研究了一种通过第三方进程在终端里启动优化的机制。 如此能够创建特定的优化管理器,该优化管理器可以实现与特定交易过程类似的交易算法过程,意即,以全自动模式运行,无需用户干预。 思路是创建一种管理滑动优化过程的算法,在该算法中,正向测试和历史时段回测均可按预设的时间间隔平移,并可彼此重叠。
这种算法优化方法比之单纯的优化,更可胜任策略稳健性测试,尽管它同时扮演了两个角色。 结果则是,我们可以发现交易系统是否稳定,并可判断系统的最优指标组合。 鉴于所论述的过程可能涉及不同机器人的系数过滤和最优组合选择方法,因此我们需要在每个时间间隔(可以是多个)内进行检查,而该过程显然难以手工执行。 甚而,我们可能会遭遇数据传输有关的错误,或与人为因素有关的其他错误。 所以,需要一些无需我们的人工干预即可从外部管理优化过程的工具。 创建的程序符合设定的目标。 为了更加体现结构化,程序创建过程分切分为若干篇文章,每篇文章都涵盖了程序创建过程的特定领域。
这一部分致力于创建一个工具箱,用于操控优化报告,可从终端导入报告,并针对所获数据进行过滤和排序。 为了提供更佳体现结构,我们将利用 *xml 文件格式。 人工和程序都可以读取该种文件里的数据。 甚至,可在文件内部将数据按模块分组,从而可以更快、更轻松地访问所需的信息。
我们的程序是采用 C# 编写的第三方进程,它类似于 MQL5 程序,需要打开并读取已创建的 *xml 文档。 所以,报告创建模块将作为 DLL 实现,如此即可在 MQL5 和 C# 两者的代码中调用。 因此,为了开发 MQL5 代码,我们将需要一个函数库。 我们将首先阐述函数库的创建过程,而下一篇文章将提供并论述与所创建函数库协同工作的 MQL5 代码,以及生成优化参数。 我们将在本文中研究这些参数。
报告结构和所需比率
如前几篇文章中已展示的那样,MetaTrader 5 可以独立下载优化通关报告,不过它提供的信息不如按照一组特定参数完成测试后在“回测”栏里生成的报告那样丰富。 为了在操控优化数据之时有更大的范围,报告应包括此栏所示的更多数据,并提供向报告中添加更多自定义数据的可能性。 出于此目的,我们将下载自行生成的报告,替代标准报告。 我们从程序所需的三种数据类型的定义开始:
- 测试器设置(整个报告的设置相同)
- 交易机器人设置(每次优化通关唯一)
- 交易结果的系数说明(每次优化通关均唯一)
<Optimisation_Report Created="06.10.2019 10:39:02"> <Optimiser_Settings> <Item Name="Bot">StockFut/StockFut.ex5</Item> <Item Name="Deposit" Currency="RUR">100000</Item> <Item Name="Leverage">1</Item> </Optimiser_Settings>
参数被写入 ” Item” 模块,每个参数都有其自己的 “Name” 属性。 存款货币将被写入 “Currency” 属性。
有基于此,文件结构应包含 2 个主要分区:测试器设置,和优化通关的描述。 我们需要在第一个分区保留三个参数:
- 机器人相对于 Experts 文件夹的路径
- 存款货币和存款
- 账户杠杆
第二个分区将包含一系列包括优化结果的模块,每个模块将包含一个系数分区,以及一组机器人参数。
<Optimisation_Results> <Result Symbol="SBRF Splice" TF="1" Start_DT="1481327340" Finish_DT="1512776940"> <Coefficients> <VaR> <Item Name="90">-1055,18214207419</Item> <Item Name="95">-1323,65133343373</Item> <Item Name="99">-1827,30841143882</Item> <Item Name="Mx">-107,03475</Item> <Item Name="Std">739,584549199836</Item> </VaR> <Max_PL_DD> <Item Name="Profit">1045,9305</Item> <Item Name="DD">-630</Item> <Item Name="Total Profit Trades">1</Item> <Item Name="Total Lose Trades">1</Item> <Item Name="Consecutive Wins">1</Item> <Item Name="Consecutive Lose">1</Item> </Max_PL_DD> <Trading_Days> <Mn> <Item Name="Profit">0</Item> <Item Name="DD">0</Item> <Item Name="Number Of Profit Trades">0</Item> <Item Name="Number Of Lose Trades">0</Item> </Mn> <Tu> <Item Name="Profit">0</Item> <Item Name="DD">0</Item> <Item Name="Number Of Profit Trades">0</Item> <Item Name="Number Of Lose Trades">0</Item> </Tu> <We> <Item Name="Profit">1045,9305</Item> <Item Name="DD">630</Item> <Item Name="Number Of Profit Trades">1</Item> <Item Name="Number Of Lose Trades">1</Item> </We> <Th> <Item Name="Profit">0</Item> <Item Name="DD">0</Item> <Item Name="Number Of Profit Trades">0</Item> <Item Name="Number Of Lose Trades">0</Item> </Th> <Fr> <Item Name="Profit">0</Item> <Item Name="DD">0</Item> <Item Name="Number Of Profit Trades">0</Item> <Item Name="Number Of Lose Trades">0</Item> </Fr> </Trading_Days> <Item Name="Payoff">1,66020714285714</Item> <Item Name="Profit factor">1,66020714285714</Item> <Item Name="Average Profit factor">0,830103571428571</Item> <Item Name="Recovery factor">0,660207142857143</Item> <Item Name="Average Recovery factor">-0,169896428571429</Item> <Item Name="Total trades">2</Item> <Item Name="PL">415,9305</Item> <Item Name="DD">-630</Item> <Item Name="Altman Z Score">0</Item> </Coefficients> <Item Name="_lot_">1</Item> <Item Name="USymbol">SBER</Item> <Item Name="Spread_in_percent">3.00000000</Item> <Item Name="UseAutoLevle">false</Item> <Item Name="max_per">174</Item> <Item Name="comission_stock">0.05000000</Item> <Item Name="shift_stock">0.00000000</Item> <Item Name="comission_fut">4.00000000</Item> <Item Name="shift_fut">0.00000000</Item> </Result> </Optimisation_Results> </Optimisation_Report>
在 Optimisation_Results 模块内部,我们将得到重复的 Result 模块,每一块都包含第 i 次的优化通关信息。 每个 Result 模块包括 4 个属性:
- Symbol
- TF
- Start_DT
- Finish_DT
这些是测试器设置,它们会依据执行优化的时间间隔而变化。 每个机器人参数都将写入 Item 模块,且以 Name 属性作为独有识别值。 机器人系数被写入 Coefficients 模块。 无法分组的系数则直接列举在 Item 模块中。 其他系数划分为几个模块:
- VaR
- 90 – 分位数 90
- 95 – 分位数 95
- 99 – 分位数 99
- Mx – 数学期望
- Std – 标准偏差
- Max_PL_DD
- Profit – 总利润
- DD – 总回撤
- Total Profit Trades – 获利交易总数
- Total Lose Trades – 亏损交易总数
- Consecutive Wins – 连续获胜交易
- Consecutive Lose – 连续亏损交易
- Trading_Days – 按天数的交易报告
- Profit – 每天平均利润
- DD – 每天平均亏损
- Number Of Profit Trades – 获利交易数量
- Number Of Lose Trades – 亏损交易数量
结果则是,我们得到了包含优化系数的结果清单,该清单充分说明了测试结果。 现在,为了筛选机器人参数,有一个完整的所需系数列表,令我们能够有效地评估机器人性能。
优化报告的包装器类,存储优化日期的类,以及 C# 形式的优化结果结构。
我们从存储特定优化通关信息数据的结构开始。
public struct ReportItem { public Dictionary<string, string> BotParams; // List of robot parameters public Coefficients OptimisationCoefficients; // Robot coefficients public string Symbol; // Symbol public int TF; // Timeframe public DateBorders DateBorders; // Date range }
所有机器人系数都存储在字符串格式的字典之中。 含有机器人参数的文件无法保存数据类型,因此,字符串格式最适合于此。 机器人系数清单提供不同的结构,类似于 *xml 优化报告中其他分组模块。 按天数的交易报告也存储在字典中。
public Dictionary<DayOfWeek, DailyData> TradingDays;
与 *xml 文件类似,DayOfWeek 和字典必须始终包含 5 天的枚举(从星期一到星期五)作为关键字。 数据存储结构中最有趣的类是 DateBorders。 类似于结构内的数据分组包含描述每个日期参数的字段,日期范围也存储在 DateBorders 结构里。
public class DateBorders : IComparable { /// <summary> /// Constructor /// </summary> /// <param name="from">Range beginning date</param> /// <param name="till">Range ending date</param> public DateBorders(DateTime from, DateTime till) { if (till <= from) throw new ArgumentException("Date 'Till' is less or equal to date 'From'"); From = from; Till = till; } /// <summary> /// From /// </summary> public DateTime From { get; } /// <summary> /// To /// </summary> public DateTime Till { get; } }
为了全功能操控日期范围,我们要能创建两个日期范围。 为此目的,覆盖 2 个运算符 “==” 和 “!=”。
相等标准则是判断两个所传递日期范围内两个日期是否相等,即开始日期匹配第二个范围的交易开始日期(交易结束日期同理)。 然而,由于对象类型是 ‘class(类实例)’,所以它可以等于 null(空),所以我们首先需要提供 与 null(空)比较的能力 。 为此目的,我们要用 is 关键字。 之后,我们可以相互比较参数,否则,如果我们尝试与 null 比较,则将返回 “null reference exception”。
#region Equal /// <summary> /// The equality comparison operator /// </summary> /// <param name="b1">Element 1</param> /// <param name="b2">Element 2</param> /// <returns>Result</returns> public static bool operator ==(DateBorders b1, DateBorders b2) { bool ans; if (b2 is null && b1 is null) ans = true; else if (b2 is null || b1 is null) ans = false; else ans = b1.From == b2.From && b1.Till == b2.Till; return ans; } /// <summary> /// The inequality comparison operator /// </summary> /// <param name="b1">Element 1</param> /// <param name="b2">Element 2</param> /// <returns>Comparison result</returns> public static bool operator !=(DateBorders b1, DateBorders b2) => !(b1 == b2); #endregion
若要重载不等式运算符,我们不再需要编写上述过程,而所有这些都已编写在运算符 ” ==” 当中。 我们需要实现的下一个功能是按时间段排序数据,这就是为什么我们需要重载运算符 “>”、”<“、”>=”、”<=”。
#region (Grater / Less) than /// <summary> /// Comparing: current element is greater than the previous one /// </summary> /// <param name="b1">Element 1</param> /// <param name="b2">Element 2</param> /// <returns>Result</returns> public static bool operator >(DateBorders b1, DateBorders b2) { if (b1 == null || b2 == null) return false; if (b1.From == b2.From) return (b1.Till > b2.Till); else return (b1.From > b2.From); } /// <summary> /// Comparing: current element is less than the previous one /// </summary> /// <param name="b1">Element 1</param> /// <param name="b2">Element 2</param> /// <returns>Result</returns> public static bool operator <(DateBorders b1, DateBorders b2) { if (b1 == null || b2 == null) return false; if (b1.From == b2.From) return (b1.Till < b2.Till); else return (b1.From < b2.From); } #endregion
如果传递给运算符的任何参数等于 null,则比较变成不可能,所以返回 False。 否则,逐一进行比较。 如果第一个时间间隔相匹配,则比较第二个时间间隔。 如果它们不相等,则只需比较第一个间隔。 因此,如果我们基于 “大于” 运算符示例阐述比较逻辑,则更大的间隔在时间上要比前一个更古老,即可按开始时间,亦或结束日期(如果开始日期相等)。 “小于” 比较逻辑类似于 “大于” 比较。
接下去要重载的运算符是启用排序选项 “大于或等于” 和 “小于或等于”。
#region Equal or (Grater / Less) than /// <summary> /// Greater than or equal comparison /// </summary> /// <param name="b1">Element 1</param> /// <param name="b2">Element 2</param> /// <returns>Result</returns> public static bool operator >=(DateBorders b1, DateBorders b2) => (b1 == b2 || b1 > b2); /// <summary> /// Less than or equal comparison /// </summary> /// <param name="b1">Element 1</param> /// <param name="b2">Element 2</param> /// <returns>Result</returns> public static bool operator <=(DateBorders b1, DateBorders b2) => (b1 == b2 || b1 < b2); #endregion
如是所见,运算符重载无需细述内部比较逻辑。 取而代之,我们利用已重载的运算符 == 和 >、<。 不过,正如 Visual Studio 在编译期间建议的那样,在重载这些运算符之外,我们还需要重载一些继承自 “object” 基类的函数。
#region override base methods (from object) /// <summary> /// Overloading of equality comparison /// </summary> /// <param name="obj">Element to compare to</param> /// <returns></returns> public override bool Equals(object obj) { if (obj is DateBorders other) return this == other; else return base.Equals(obj); } /// <summary> /// Cast the class to a string and return its hash code /// </summary> /// <returns>String hash code</returns> public override int GetHashCode() { return ToString().GetHashCode(); } /// <summary> /// Convert the current class to a string /// </summary> /// <returns>String From date - To date</returns> public override string ToString() { return $"{From}-{Till}"; } #endregion /// <summary> /// Compare the current element with the passed one /// </summary> /// <param name="obj"></param> /// <returns></returns> public int CompareTo(object obj) { if (obj == null) return 1; if (obj is DateBorders borders) { if (this == borders) return 0; else if (this < borders) return -1; else return 1; } else { throw new ArgumentException("object is not DateBorders"); } }
Equals 方法: 即可用重载运算符 ==(如果所传递对象的类型为 DateBorders),亦或重载方法的基本实现。
ToString 方法: 重载其实现,表示为由连字符 “-” 分隔的两个日期字符串。 这有助于我们重载 GetHashCode 方法。
GetHashCode 方法: 重载其实现,首先将对象转换为字符串,然后返回该字符串的哈希码。 当利用 C# 创建新的类实例时,无论类的内容如何,其哈希码都是唯一的。 也就是说,如果我们不重载该方法,并创建两个 DateBorders 类的实例,它们内部的 From 和 To 日期相同,则尽管内容相同,它们仍将拥有不同的哈希码。 该规则不适用于字符串,因为 C# 提供了一种机制,该机制可防止先前已创建的字符串再次被创建新的 String 类实例 — 因此,相同字符串的哈希码将匹配。 利用 ToString 方法重载,并利用字符串哈希码,我们所提供的类哈希码的行为与 String 类似。 现在,当使用 IEnumerable.Distinct 方法时,我们可以保证接收唯一日期范围列表的逻辑将是正确的,因为该方法基于比较对象的哈希码。
在我们的类中,实现继承的 IComparable 接口,即我们实现了 CompareTo 方法,该方法用当前类实例与所传递的实例进行比较。 它的实现很容易,并用到以前重载的运算符。
实现了所需的重载后,我们可以更有效地运用该类。 我们可以:
- 比较两个实例是否相等
- 比较两个实例大于/小于
- 比较两个实例是否大于或等于/小于或等于
- 按升/降排序
- 从日期范围列表中获取唯一值
- 使用 IEnumerable.Sort 方法以降序对列表进行排序,并使用 IComparable 接口。
由于我们正在实现滚动优化,而这会涉及回测和正向测试,因此我们需要创建一种方法来比较历史间隔和正向间隔。
/// <summary> /// Method for comparing forward and historical optimizations /// </summary> /// <param name="History">Array of historical optimization</param> /// <param name="Forward">Array of forward optimizations</param> /// <returns>Sorted list historical - forward optimization</returns> public static Dictionary<DateBorders, DateBorders> CompareHistoryToForward(List<DateBorders> History, List<DateBorders> Forward) { // array of comparable optimizations Dictionary<DateBorders, DateBorders> ans = new Dictionary<DateBorders, DateBorders>(); // Sort the passed parameters History.Sort(); Forward.Sort(); // Create a historical optimization loop int i = 0; foreach (var item in History) { if(ans.ContainsKey(item)) continue; ans.Add(item, null); // Add historical optimization if (Forward.Count <= i) continue; // If the array of forward optimization is less than the index, continue the loop // Forward optimization loop for (int j = i; j < Forward.Count; j++) { // If the current forward optimization is contained in the results array, skip if (ans.ContainsValue(Forward[j]) || Forward[j].From < item.Till) { continue; } // Compare forward and historical optimization ans[item] = Forward[j]; i = j + 1; break; } } return ans; }
如您所见,该方法是静态的。 这样做是为了令其可以作为例行函数使用,而不必与特定的类实例绑定。 首先,它按升序对所传递的时间间隔进行排序。 因此,在下一个循环中,我们可以确切地知道所有先前传递的间隔都小于或等于下一个间隔。 然后实现两个循环: foreach 用于历史间隔,嵌套循环 用于正向间隔。
在历史数据循环的开始处,我们总是将历史范围(关键字)添加到结果集合,并将正向间隔暂时设置为 null。 正向结果循环从 第 i 个参数开始。 这样可以防止正向列表中已处理完毕元素的重复循环。 此即,正向间隔应始终跟随历史间隔之后,即应大于历史间隔。 这就是为什么我们按正向时间间隔实现循环的原因,以防在所传递列表中,先于第一个历史间隔出现一个正向周期,而其时间间隔早于第一个历史时间间隔。 最好在表格中具现该想法:
| 历史 | 前向 | ||
|---|---|---|---|
| 开始 | 结束 | 开始 | 结束 |
| 10.03.2016 | 09.03.2017 | 12.12.2016 | 09.03.2017 |
| 10.06.2016 | 09.06.2017 | 10.03.2017 | 09.06.2017 |
| 10.09.2016 | 09.09.2017 | 10.06.2017 | 09.09.2017 |
因此,第一个历史间隔在 2017 年 3 月 9 日结束,而第一个正向间隔在 2016 年 12 月 12 日开始,这是不正确的。 这就是为什么我们要略过正向间隔循环,即依据该条件。 还有,要略过包含在结果字典中的正向间隔。如果结果字典中尚不存在第 j 个正向数据,并且正向间隔的开始日期 >= 当前历史间隔的结束日期,则保存所接收数值,并退出正向间隔循环,因为已找到所需数值。 退出之前,将正向间隔数值赋值给选定间隔之后的第 i 个变量(该变量表示正向列表迭代开始。 这样做是因为不再需要当前间隔(由于初始数据已排序)。
历史优化之前的检查可确保所有历史优化都是唯一的。 因此,在结果字典中获得以下列表:
| 关键字 | 数值 |
|---|---|
| 10.03.2016-09.3.2017 | 10.03.2017-09.06.2017 |
| 10.06.2016-09.06.2017 | 10.06.2017-09.09.2017 |
| 10.09.2016-09.09.2017 | null |
从提供的数据中可以看出,第一个正向间隔被丢弃,最后一个历史间隔没有发现间隔,因为没有传递这个间隔。 基于此逻辑,程序将比较历史间隔和正向间隔的数据,并将厘清哪个历史间隔应作为正向优化测试的参数。
为了依据特定优化结果实现高效的操作,我为 ReportItem 结构创建了一个包装器结构,其中包含许多附加方法和重载的运算符。 基本上,包装器包含两个字段:
/// <summary> /// Optimization pass report /// </summary> public ReportItem report; /// <summary> /// Sorting factor /// </summary> public double SortBy;
以上描述了第一个字段。 创建第二个字段是为了启用按多个数值进行排序,例如利润和回报率。 排序机制将在后面论述,但是其思路是将这些数值转换为一个,并将其存储在此变量中。
该结构还包含类型转换重载:
/// <summary> /// The operator of implicit type conversion from optimization pass to the current type /// </summary> /// <param name="item">Optimization pass report</param> public static implicit operator OptimisationResult(ReportItem item) { return new OptimisationResult { report = item, SortBy = 0 }; } /// <summary> /// The operator of explicit type conversion from current to the optimization pass structure /// </summary> /// <param name="optimisationResult">current type</param> public static explicit operator ReportItem(OptimisationResult optimisationResult) { return optimisationResult.report; }
结果则为,我们可以将 ReportItem 类型隐式转换为其包装器,然后将 ReportItem 包装器显式转换为交易报告元素。 这比顺序填充字段更有效。 由于 ReportItem 结构中的所有字段已划分为几类,有时为了接收所需的数值我们也许需要很长的代码。 已经创建了一种特殊的方法来节省空间,并创建更通用的取值器。 它从上面的 GetResult(SortBy resultType) 代码接收所传递的的枚举 SourtBy,其中内含机器人的比率数据。 实现很简单,但是太长了,因此不在此处列出。 该方法迭代所传递的枚举,并利用 switch 结构返回所请求系数的数值。 由于大多数系数的类型为 double,且此类型可以包含所有其他数字类型,因此系数值将转换为 double。
此包装器类型还实现了比较运算符的重载:
/// <summary> /// Overloading of the equality comparison operator /// </summary> /// <param name="result1">Parameter 1 to compare</param> /// <param name="result2">Parameter 2 to compare</param> /// <returns>Comparison result</returns> public static bool operator ==(OptimisationResult result1, OptimisationResult result2) { foreach (var item in result1.report.BotParams) { if (!result2.report.BotParams.ContainsKey(item.Key)) return false; if (result2.report.BotParams[item.Key] != item.Value) return false; } return true; } /// <summary> /// Overloading of the inequality comparison operator /// </summary> /// <param name="result1">Parameter 1 to compare</param> /// <param name="result2">Parameter 2 to compare</param> /// <returns>Comparison result</returns> public static bool operator !=(OptimisationResult result1, OptimisationResult result2) { return !(result1 == result2); } /// <summary> /// Overloading of the basic type comparison operator /// </summary> /// <param name="obj"></param> /// <returns></returns> public override bool Equals(object obj) { if (obj is OptimisationResult other) { return this == other; } else return base.Equals(obj); }
包含相同名称和机器人参数值的优化元素会被视为相等。 因此,如果我们需要比较两个优化通关信息,则我们已有了现成的重载运算符。 该结构还包含将数据写入文件的方法。 如果存在,则简单地将数据添加到文件之中。 数据写入元素和方法的实现会在后面加以解释。
创建文件来存储优化报告
我们将操控优化报告,不仅将它们输出到终端,还将输出到所创建的程序。 此即为什么我们将优化报告创建方法添加到 DLL 的原因。 我们还提供若干种将数据写入文件的方法,即,允许将数据数组写入文件,以及向现有文件添加单独的元素(如果该文件不存在,则应创建它)。 最后一个方法将导入到终端,并将在 C# 类中使用。 我们开始研究已实现的报告文件写入方法,通过与附加数据相连的函数输出至文件。 为此目的,创建了 ReportWriter 类。 完整的类实现在随附的项目文件之中。 在此,我只展示最有趣的那些方法。 我们首先阐述该类如何工作。
它仅包含静态方法:如此可将其方法导出到 MQL5。 出于相同的目的,该类以公开访问修饰符标记。 此类包含 ReportItem 类型的静态字段和许多方法,可向其交替添加系数和 EA 参数。
/// <summary> /// temporary data keeper /// </summary> private static ReportItem ReportItem; /// <summary> /// clearing the temporary data keeper /// </summary> public static void ClearReportItem() { ReportItem = new ReportItem(); }
另一个方法 ClearReportItem()。 它重新创建该字段实例。 当我们无法访问先前对象实例的情况下:其已被删除,则数据保存过程再次开始。 数据添加方法按模块分组。 此为这些方法的签章。
/// <summary> /// Add robot parameters /// </summary> /// <param name="name">Parameter name</param> /// <param name="value">Parameter value</param> public static void AppendBotParam(string name, string value); /// <summary> /// Add the main list of coefficients /// </summary> /// <param name="payoff"></param> /// <param name="profitFactor"></param> /// <param name="averageProfitFactor"></param> /// <param name="recoveryFactor"></param> /// <param name="averageRecoveryFactor"></param> /// <param name="totalTrades"></param> /// <param name="pl"></param> /// <param name="dd"></param> /// <param name="altmanZScore"></param> public static void AppendMainCoef(double payoff, double profitFactor, double averageProfitFactor, double recoveryFactor, double averageRecoveryFactor, int totalTrades, double pl, double dd, double altmanZScore); /// <summary> /// Add VaR /// </summary> /// <param name="Q_90"></param> /// <param name="Q_95"></param> /// <param name="Q_99"></param> /// <param name="Mx"></param> /// <param name="Std"></param> public static void AppendVaR(double Q_90, double Q_95, double Q_99, double Mx, double Std); /// <summary> /// Add total PL / DD and associated values /// </summary> /// <param name="profit"></param> /// <param name="dd"></param> /// <param name="totalProfitTrades"></param> /// <param name="totalLoseTrades"></param> /// <param name="consecutiveWins"></param> /// <param name="consecutiveLose"></param> public static void AppendMaxPLDD(double profit, double dd, int totalProfitTrades, int totalLoseTrades, int consecutiveWins, int consecutiveLose); /// <summary> /// Add a specific day /// </summary> /// <param name="day"></param> /// <param name="profit"></param> /// <param name="dd"></param> /// <param name="numberOfProfitTrades"></param> /// <param name="numberOfLoseTrades"></param> public static void AppendDay(int day, double profit, double dd, int numberOfProfitTrades, int numberOfLoseTrades);
该方法每 5 个交易日调用一次,并添加按天细分的交易统计信息。 如果我们某天或几天没加它,则以后将不会读取该写入文件。 一旦将数据添加到数据存储字段后,我们可以继续记录该字段。 在此之前,检查文件是否存在,如必要则创建它。 添加了一些创建文件的方法。
/// <summary> /// The method creates the file if it has not been created /// </summary> /// <param name="pathToBot">Path to the robot</param> /// <param name="currency">Deposit currency</param> /// <param name="balance">Balance</param> /// <param name="leverage">Leverage</param> /// <param name="pathToFile">Path to file</param> private static void CreateFileIfNotExists(string pathToBot, string currency, double balance, int leverage, string pathToFile) { if (File.Exists(pathToFile)) return; using (var xmlWriter = new XmlTextWriter(pathToFile, null)) { // set document format xmlWriter.Formatting = Formatting.Indented; xmlWriter.IndentChar = '/t'; xmlWriter.Indentation = 1; xmlWriter.WriteStartDocument(); // Create document root #region Document root xmlWriter.WriteStartElement("Optimisation_Report"); // Write the creation date xmlWriter.WriteStartAttribute("Created"); xmlWriter.WriteString(DateTime.Now.ToString("dd.MM.yyyy HH:mm:ss")); xmlWriter.WriteEndAttribute(); #region Optimiser settings section // Optimizer settings xmlWriter.WriteStartElement("Optimiser_Settings"); // Path to the robot WriteItem(xmlWriter, "Bot", pathToBot); // Deposit WriteItem(xmlWriter, "Deposit", balance.ToString(), new Dictionary<string, string> { { "Currency", currency } }); // Leverage WriteItem(xmlWriter, "Leverage", leverage.ToString()); xmlWriter.WriteEndElement(); #endregion #region Optimization results section // the root node of the optimization results list xmlWriter.WriteStartElement("Optimisation_Results"); xmlWriter.WriteEndElement(); #endregion xmlWriter.WriteEndElement(); #endregion xmlWriter.WriteEndDocument(); xmlWriter.Close(); } } /// <summary> /// Write element to a file /// </summary> /// <param name="writer">Writer</param> /// <param name="Name">Element name</param> /// <param name="Value">Element value</param> /// <param name="Attributes">Attributes</param> private static void WriteItem(XmlTextWriter writer, string Name, string Value, Dictionary<string, string> Attributes = null) { writer.WriteStartElement("Item"); writer.WriteStartAttribute("Name"); writer.WriteString(Name); writer.WriteEndAttribute(); if (Attributes != null) { foreach (var item in Attributes) { writer.WriteStartAttribute(item.Key); writer.WriteString(item.Value); writer.WriteEndAttribute(); } } writer.WriteString(Value); writer.WriteEndElement(); }
我于此还提供了 WriteItem 方法的实现,该方法包含一些重复代码,用于向文件中添加含有特定属性和数据的最终元素。 文件创建方法 CreateFileIfNotExists 检查文件是否存在,创建文件并形成所需的最小文件结构。
首先,它创建文件的根,即 <Optimization_Report/> 标记,文件的所有子结构都位于该根之内。 然后,填写文件创建数据 — 如此实现是为了今后操控文件更便利。 之后,我们创建一个无变化优化器设置节点并指定它们。 然后创建一个存储优化结果的分区,并立即将其封闭。 结果则是,我们得到一个满足最低格式要求的空文件。
<Optimisation_Report Created="24.10.2019 19:10:08"> <Optimiser_Settings> <Item Name="Bot">Path to bot</Item> <Item Name="Deposit" Currency="Currency">1000</Item> <Item Name="Leverage">1</Item> </Optimiser_Settings> <Optimisation_Results /> </Optimisation_Report>
因此,我们能够利用 XmlDocument 类读取此文件。 这是读取和编辑已有 Xml 文档最有用的类。 我们将完全依靠该类往已有文档中添加数据。 重复操作是作为单独的方法实现的,因此我们能够更有效地将数据添加到已有文档中:
/// <summary> /// Writing attributes to a file /// </summary> /// <param name="item">Node</param> /// <param name="xmlDoc">Document</param> /// <param name="Attributes">Attributes</param> private static void FillInAttributes(XmlNode item, XmlDocument xmlDoc, Dictionary<string, string> Attributes) { if (Attributes != null) { foreach (var attr in Attributes) { XmlAttribute attribute = xmlDoc.CreateAttribute(attr.Key); attribute.Value = attr.Value; item.Attributes.Append(attribute); } } } /// <summary> /// Add section /// </summary> /// <param name="xmlDoc">Document</param> /// <param name="xpath_parentSection">xpath to select parent node</param> /// <param name="sectionName">Section name</param> /// <param name="Attributes">Attribute</param> private static void AppendSection(XmlDocument xmlDoc, string xpath_parentSection, string sectionName, Dictionary<string, string> Attributes = null) { XmlNode section = xmlDoc.SelectSingleNode(xpath_parentSection); XmlNode item = xmlDoc.CreateElement(sectionName); FillInAttributes(item, xmlDoc, Attributes); section.AppendChild(item); } /// <summary> /// Write item /// </summary> /// <param name="xmlDoc">Document</param> /// <param name="xpath_parentSection">xpath to select parent node</param> /// <param name="name">Item name</param> /// <param name="value">Value</param> /// <param name="Attributes">Attributes</param> private static void WriteItem(XmlDocument xmlDoc, string xpath_parentSection, string name, string value, Dictionary<string, string> Attributes = null) { XmlNode section = xmlDoc.SelectSingleNode(xpath_parentSection); XmlNode item = xmlDoc.CreateElement(name); item.InnerText = value; FillInAttributes(item, xmlDoc, Attributes); section.AppendChild(item); }
第一个方法 FillInAttributes 为所传递的节点填充属性,WriteItem 将一个数据项写入到 XPath 指定的分区,而 AppendSection 在另一个分区之内添加一个由所传递 Xpath 路径指定的分区。 在将数据添加到文件时,经常使用这些代码块。 数据写入方法相当冗长,且其划分为多个模块。
/// <summary> /// Write trading results to a file /// </summary> /// <param name="pathToBot">Path to the bot</param> /// <param name="currency">Deposit currency</param> /// <param name="balance">Balance</param> /// <param name="leverage">Leverage</param> /// <param name="pathToFile">Path to file</param> /// <param name="symbol">Symbol</param> /// <param name="tf">Timeframe</param> /// <param name="StartDT">Trading start dare</param> /// <param name="FinishDT">Trading end date</param> public static void Write(string pathToBot, string currency, double balance, int leverage, string pathToFile, string symbol, int tf, ulong StartDT, ulong FinishDT) { // Create the file if it does not yet exist CreateFileIfNotExists(pathToBot, currency, balance, leverage, pathToFile); ReportItem.Symbol = symbol; ReportItem.TF = tf; // Create a document and read the file using it XmlDocument xmlDoc = new XmlDocument(); xmlDoc.Load(pathToFile); #region Append result section // Write a request to switch to the optimization results section string xpath = "Optimisation_Report/Optimisation_Results"; // Add a new section with optimization results AppendSection(xmlDoc, xpath, "Result", new Dictionary<string, string> { { "Symbol", symbol }, { "TF", tf.ToString() }, { "Start_DT", StartDT.ToString() }, { "Finish_DT", FinishDT.ToString() } }); // Add section with optimization results AppendSection(xmlDoc, $"{xpath}/Result[last()]", "Coefficients"); // Add section with VaR AppendSection(xmlDoc, $"{xpath}/Result[last()]/Coefficients", "VaR"); // Add section with total PL / DD AppendSection(xmlDoc, $"{xpath}/Result[last()]/Coefficients", "Max_PL_DD"); // Add section with trading results by days AppendSection(xmlDoc, $"{xpath}/Result[last()]/Coefficients", "Trading_Days"); // Add section with trading results on Monday AppendSection(xmlDoc, $"{xpath}/Result[last()]/Coefficients/Trading_Days", "Mn"); // Add section with trading results on Tuesday AppendSection(xmlDoc, $"{xpath}/Result[last()]/Coefficients/Trading_Days", "Tu"); // Add section with trading results on Wednesday AppendSection(xmlDoc, $"{xpath}/Result[last()]/Coefficients/Trading_Days", "We"); // Add section with trading results on Thursday AppendSection(xmlDoc, $"{xpath}/Result[last()]/Coefficients/Trading_Days", "Th"); // Add section with trading results on Friday AppendSection(xmlDoc, $"{xpath}/Result[last()]/Coefficients/Trading_Days", "Fr"); #endregion #region Append Bot params // Iterate through bot parameters foreach (var item in ReportItem.BotParams) { // Write the selected robot parameter WriteItem(xmlDoc, "Optimisation_Report/Optimisation_Results/Result[last()]", "Item", item.Value, new Dictionary<string, string> { { "Name", item.Key } }); } #endregion #region Append main coef // Set path to node with coefficients xpath = "Optimisation_Report/Optimisation_Results/Result[last()]/Coefficients"; // Save coefficients WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.Payoff.ToString(), new Dictionary<string, string> { { "Name", "Payoff" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.ProfitFactor.ToString(), new Dictionary<string, string> { { "Name", "Profit factor" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.AverageProfitFactor.ToString(), new Dictionary<string, string> { { "Name", "Average Profit factor" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.RecoveryFactor.ToString(), new Dictionary<string, string> { { "Name", "Recovery factor" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.AverageRecoveryFactor.ToString(), new Dictionary<string, string> { { "Name", "Average Recovery factor" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.TotalTrades.ToString(), new Dictionary<string, string> { { "Name", "Total trades" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.PL.ToString(), new Dictionary<string, string> { { "Name", "PL" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.DD.ToString(), new Dictionary<string, string> { { "Name", "DD" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.AltmanZScore.ToString(), new Dictionary<string, string> { { "Name", "Altman Z Score" } }); #endregion #region Append VaR // Set path to node with VaR xpath = "Optimisation_Report/Optimisation_Results/Result[last()]/Coefficients/VaR"; // Save VaR results WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.VaR.Q_90.ToString(), new Dictionary<string, string> { { "Name", "90" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.VaR.Q_95.ToString(), new Dictionary<string, string> { { "Name", "95" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.VaR.Q_99.ToString(), new Dictionary<string, string> { { "Name", "99" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.VaR.Mx.ToString(), new Dictionary<string, string> { { "Name", "Mx" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.VaR.Std.ToString(), new Dictionary<string, string> { { "Name", "Std" } }); #endregion #region Append max PL and DD // Set path to node with total PL / DD xpath = "Optimisation_Report/Optimisation_Results/Result[last()]/Coefficients/Max_PL_DD"; // Save coefficients WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.MaxPLDD.Profit.Value.ToString(), new Dictionary<string, string> { { "Name", "Profit" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.MaxPLDD.DD.Value.ToString(), new Dictionary<string, string> { { "Name", "DD" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.MaxPLDD.Profit.TotalTrades.ToString(), new Dictionary<string, string> { { "Name", "Total Profit Trades" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.MaxPLDD.DD.TotalTrades.ToString(), new Dictionary<string, string> { { "Name", "Total Lose Trades" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.MaxPLDD.Profit.ConsecutivesTrades.ToString(), new Dictionary<string, string> { { "Name", "Consecutive Wins" } }); WriteItem(xmlDoc, xpath, "Item", ReportItem.OptimisationCoefficients.MaxPLDD.DD.ConsecutivesTrades.ToString(), new Dictionary<string, string> { { "Name", "Consecutive Lose" } }); #endregion #region Append Days foreach (var item in ReportItem.OptimisationCoefficients.TradingDays) { // Set path to specific day node xpath = "Optimisation_Report/Optimisation_Results/Result[last()]/Coefficients/Trading_Days"; // Select day switch (item.Key) { case DayOfWeek.Monday: xpath += "/Mn"; break; case DayOfWeek.Tuesday: xpath += "/Tu"; break; case DayOfWeek.Wednesday: xpath += "/We"; break; case DayOfWeek.Thursday: xpath += "/Th"; break; case DayOfWeek.Friday: xpath += "/Fr"; break; } // Save results WriteItem(xmlDoc, xpath, "Item", item.Value.Profit.Value.ToString(), new Dictionary<string, string> { { "Name", "Profit" } }); WriteItem(xmlDoc, xpath, "Item", item.Value.DD.Value.ToString(), new Dictionary<string, string> { { "Name", "DD" } }); WriteItem(xmlDoc, xpath, "Item", item.Value.Profit.Trades.ToString(), new Dictionary<string, string> { { "Name", "Number Of Profit Trades" } }); WriteItem(xmlDoc, xpath, "Item", item.Value.DD.Trades.ToString(), new Dictionary<string, string> { { "Name", "Number Of Lose Trades" } }); } #endregion // Rewrite the file with the changes xmlDoc.Save(pathToFile); // Clear the variable which stored results written to a file ClearReportItem(); }
首先,我们将整个文档加载到内存中,然后添加分区。 我们研究将路径传递到根节点的 Xpath 请求格式。
$"{xpath}/Result[last()]/Coefficients"
该 xpath 变量包含存储优化通关信息元素的节点路径。 该节点存储优化结果节点,据其可体现为结构数组。 Result [last()] 构造选择数组的最后一个元素,然后将路径传递给嵌套的 /Coefficients 节点。 遵照论述的原理,我们选择所需的优化结果节点。
下一步是添加机器人参数:在循环中,我们将参数直接添加到结果目录。 然后将系数数量添加到系数目录中。 这些附加分为多个模块。 结果表现为,我们保存了结果并清除了临时存储。 结果则为,我们得到一个包含参数和优化结果列表的文件。 由不同进程启动的异步操作期间(在测试器中进行优化,会使用多个处理器),为了分离线程,已创建了另一种写入方法,该方法利用命名的互斥体来分离线程。
/// <summary> /// Write to file while locking using a named mutex /// </summary> /// <param name="mutexName">Mutex name</param> /// <param name="pathToBot">Path to the bot</param> /// <param name="currency">Deposit currency</param> /// <param name="balance">Balance</param> /// <param name="leverage">Leverage</param> /// <param name="pathToFile">Path to file</param> /// <param name="symbol">Symbol</param> /// <param name="tf">Timeframe</param> /// <param name="StartDT">Trading start dare</param> /// <param name="FinishDT">Trading end date</param> /// <returns></returns> public static string MutexWriter(string mutexName, string pathToBot, string currency, double balance, int leverage, string pathToFile, string symbol, int tf, ulong StartDT, ulong FinishDT) { string ans = ""; // Mutex lock Mutex m = new Mutex(false, mutexName); m.WaitOne(); try { // write to file Write(pathToBot, currency, balance, leverage, pathToFile, symbol, tf, StartDT, FinishDT); } catch (Exception e) { // Catch error if any ans = e.Message; } // Release the mutex m.ReleaseMutex(); // Return error text return ans; }
该方法使用以前的方法写入数据,但是写入过程由互斥体包装在 try-catch 代码块中。 最后一个启用了互斥锁释放,即使发生错误也会如此。 否则,该过程可能会死锁,优化也许无法继续。 这些方法还用于 WriteResult 方法的 OptimisationResult 结构中。
/// <summary> /// The method adds current parameter to the existing file or creates a new file with the current parameter /// </summary> /// <param name="pathToBot">Relative path to the robot from the Experts folder</param> /// <param name="currency">Deposit currency</param> /// <param name="balance">Balance</param> /// <param name="leverage">Leverage</param> /// <param name="pathToFile">Path to file</param> public void WriteResult(string pathToBot, string currency, double balance, int leverage, string pathToFile) { try { foreach (var param in report.BotParams) { ReportWriter.AppendBotParam(param.Key, param.Value); } ReportWriter.AppendMainCoef(GetResult(ReportManager.SortBy.Payoff), GetResult(ReportManager.SortBy.ProfitFactor), GetResult(ReportManager.SortBy.AverageProfitFactor), GetResult(ReportManager.SortBy.RecoveryFactor), GetResult(ReportManager.SortBy.AverageRecoveryFactor), (int)GetResult(ReportManager.SortBy.TotalTrades), GetResult(ReportManager.SortBy.PL), GetResult(ReportManager.SortBy.DD), GetResult(ReportManager.SortBy.AltmanZScore)); ReportWriter.AppendVaR(GetResult(ReportManager.SortBy.Q_90), GetResult(ReportManager.SortBy.Q_95), GetResult(ReportManager.SortBy.Q_99), GetResult(ReportManager.SortBy.Mx), GetResult(ReportManager.SortBy.Std)); ReportWriter.AppendMaxPLDD(GetResult(ReportManager.SortBy.ProfitFactor), GetResult(ReportManager.SortBy.MaxDD), (int)GetResult(ReportManager.SortBy.MaxProfitTotalTrades), (int)GetResult(ReportManager.SortBy.MaxDDTotalTrades), (int)GetResult(ReportManager.SortBy.MaxProfitConsecutivesTrades), (int)GetResult(ReportManager.SortBy.MaxDDConsecutivesTrades)); foreach (var day in report.OptimisationCoefficients.TradingDays) { ReportWriter.AppendDay((int)day.Key, day.Value.Profit.Value, day.Value.Profit.Value, day.Value.Profit.Trades, day.Value.DD.Trades); } ReportWriter.Write(pathToBot, currency, balance, leverage, pathToFile, report.Symbol, report.TF, report.DateBorders.From.DTToUnixDT(), report.DateBorders.Till.DTToUnixDT()); } catch (Exception e) { ReportWriter.ClearReportItem(); throw e; } }
在该方法中,我们将优化结果交替添加到临时存储中,然后调用 Write 方法将其保存到已有文件中,或者若文件尚未创建,则创建一个新文件。
所述方法将获得的所需数据信息写入准备好的文件当中。 当需要写入一系列数据时,还有另一个更适合的方法。 该方法已作为 IEnumerable <OptimisationResult> 接口的扩展进行了开发。 现在,我们可以保存来自相应接口继承的所有列表数据。
public static void ReportWriter(this IEnumerable<OptimisationResult> results, string pathToBot, string currency, double balance, int leverage, string pathToFile) { // Delete the file if it exists if (File.Exists(pathToFile)) File.Delete(pathToFile); // Create writer using (var xmlWriter = new XmlTextWriter(pathToFile, null)) { // Set document format xmlWriter.Formatting = Formatting.Indented; xmlWriter.IndentChar = '/t'; xmlWriter.Indentation = 1; xmlWriter.WriteStartDocument(); // The root node of the document xmlWriter.WriteStartElement("Optimisation_Report"); // Write attributes WriteAttribute(xmlWriter, "Created", DateTime.Now.ToString("dd.MM.yyyy HH:mm:ss")); // Write optimizer settings to file #region Optimiser settings section xmlWriter.WriteStartElement("Optimiser_Settings"); WriteItem(xmlWriter, "Bot", pathToBot); // path to the robot WriteItem(xmlWriter, "Deposit", balance.ToString(), new Dictionary<string, string> { { "Currency", currency } }); // Currency and deposit WriteItem(xmlWriter, "Leverage", leverage.ToString()); // Leverage xmlWriter.WriteEndElement(); #endregion // Write optimization results to the file #region Optimisation result section xmlWriter.WriteStartElement("Optimisation_Results"); // Loop through optimization results foreach (var item in results) { // Write specific result xmlWriter.WriteStartElement("Result"); // Write attributes of this optimization pass WriteAttribute(xmlWriter, "Symbol", item.report.Symbol); // Symbol WriteAttribute(xmlWriter, "TF", item.report.TF.ToString()); // Timeframe WriteAttribute(xmlWriter, "Start_DT", item.report.DateBorders.From.DTToUnixDT().ToString()); // Optimization start date WriteAttribute(xmlWriter, "Finish_DT", item.report.DateBorders.Till.DTToUnixDT().ToString()); // Optimization end date // Write optimization result WriteResultItem(item, xmlWriter); xmlWriter.WriteEndElement(); } xmlWriter.WriteEndElement(); #endregion xmlWriter.WriteEndElement(); xmlWriter.WriteEndDocument(); xmlWriter.Close(); } }
该方法将优化报告逐一写入文件,直到数组中没有更多数据为止。 如果在所传递路径中已有文件存在,它将被新文件所替代。 首先我们创建文件写入器,并进行配置。 然后,按照已知的文件结构,我们依次写入优化设置和优化结果。 从上面的代码摘录可以看出,在一个循环中输出结果,该循环遍历集合的元素,在其实例中调用了所述的方法。 在循环内部,数据输出会委托给专门创建的方法,该方法将特定元素的数据写入文件。
/// <summary> /// Write a specific optimization pass /// </summary> /// <param name="resultItem">Optimization pass value</param> /// <param name="writer">Writer</param> private static void WriteResultItem(OptimisationResult resultItem, XmlTextWriter writer) { // Write coefficients #region Coefficients writer.WriteStartElement("Coefficients"); // Write VaR #region VaR writer.WriteStartElement("VaR"); WriteItem(writer, "90", resultItem.GetResult(SortBy.Q_90).ToString()); // Quantile 90 WriteItem(writer, "95", resultItem.GetResult(SortBy.Q_95).ToString()); // Quantile 95 WriteItem(writer, "99", resultItem.GetResult(SortBy.Q_99).ToString()); // Quantile 99 WriteItem(writer, "Mx", resultItem.GetResult(SortBy.Mx).ToString()); // Average for PL WriteItem(writer, "Std", resultItem.GetResult(SortBy.Std).ToString()); // Standard deviation for PL writer.WriteEndElement(); #endregion // Write PL / DD parameters - extreme points #region Max PL DD writer.WriteStartElement("Max_PL_DD"); WriteItem(writer, "Profit", resultItem.GetResult(SortBy.MaxProfit).ToString()); // Total profit WriteItem(writer, "DD", resultItem.GetResult(SortBy.MaxDD).ToString()); // Total loss WriteItem(writer, "Total Profit Trades", ((int)resultItem.GetResult(SortBy.MaxProfitTotalTrades)).ToString()); // Total number of winning trades WriteItem(writer, "Total Lose Trades", ((int)resultItem.GetResult(SortBy.MaxDDTotalTrades)).ToString()); // Total number of losing trades WriteItem(writer, "Consecutive Wins", ((int)resultItem.GetResult(SortBy.MaxProfitConsecutivesTrades)).ToString()); // Winning trades in a row WriteItem(writer, "Consecutive Lose", ((int)resultItem.GetResult(SortBy.MaxDDConsecutivesTrades)).ToString()); // Losing trades in a row writer.WriteEndElement(); #endregion // Write trading results by days #region Trading_Days // The method writing trading results void AddDay(string Day, double Profit, double DD, int ProfitTrades, int DDTrades) { writer.WriteStartElement(Day); WriteItem(writer, "Profit", Profit.ToString()); // Profits WriteItem(writer, "DD", DD.ToString()); // Losses WriteItem(writer, "Number Of Profit Trades", ProfitTrades.ToString()); // Number of profitable trades WriteItem(writer, "Number Of Lose Trades", DDTrades.ToString()); // Number of losing trades writer.WriteEndElement(); } writer.WriteStartElement("Trading_Days"); // Monday AddDay("Mn", resultItem.GetResult(SortBy.AverageDailyProfit_Mn), resultItem.GetResult(SortBy.AverageDailyDD_Mn), (int)resultItem.GetResult(SortBy.AverageDailyProfitTrades_Mn), (int)resultItem.GetResult(SortBy.AverageDailyDDTrades_Mn)); // Tuesday AddDay("Tu", resultItem.GetResult(SortBy.AverageDailyProfit_Tu), resultItem.GetResult(SortBy.AverageDailyDD_Tu), (int)resultItem.GetResult(SortBy.AverageDailyProfitTrades_Tu), (int)resultItem.GetResult(SortBy.AverageDailyDDTrades_Tu)); // Wednesday AddDay("We", resultItem.GetResult(SortBy.AverageDailyProfit_We), resultItem.GetResult(SortBy.AverageDailyDD_We), (int)resultItem.GetResult(SortBy.AverageDailyProfitTrades_We), (int)resultItem.GetResult(SortBy.AverageDailyDDTrades_We)); // Thursday AddDay("Th", resultItem.GetResult(SortBy.AverageDailyProfit_Th), resultItem.GetResult(SortBy.AverageDailyDD_Th), (int)resultItem.GetResult(SortBy.AverageDailyProfitTrades_Th), (int)resultItem.GetResult(SortBy.AverageDailyDDTrades_Th)); // Friday AddDay("Fr", resultItem.GetResult(SortBy.AverageDailyProfit_Fr), resultItem.GetResult(SortBy.AverageDailyDD_Fr), (int)resultItem.GetResult(SortBy.AverageDailyProfitTrades_Fr), (int)resultItem.GetResult(SortBy.AverageDailyDDTrades_Fr)); writer.WriteEndElement(); #endregion // Write other coefficients WriteItem(writer, "Payoff", resultItem.GetResult(SortBy.Payoff).ToString()); WriteItem(writer, "Profit factor", resultItem.GetResult(SortBy.ProfitFactor).ToString()); WriteItem(writer, "Average Profit factor", resultItem.GetResult(SortBy.AverageProfitFactor).ToString()); WriteItem(writer, "Recovery factor", resultItem.GetResult(SortBy.RecoveryFactor).ToString()); WriteItem(writer, "Average Recovery factor", resultItem.GetResult(SortBy.AverageRecoveryFactor).ToString()); WriteItem(writer, "Total trades", ((int)resultItem.GetResult(SortBy.TotalTrades)).ToString()); WriteItem(writer, "PL", resultItem.GetResult(SortBy.PL).ToString()); WriteItem(writer, "DD", resultItem.GetResult(SortBy.DD).ToString()); WriteItem(writer, "Altman Z Score", resultItem.GetResult(SortBy.AltmanZScore).ToString()); writer.WriteEndElement(); #endregion // Write robot coefficients #region Bot params foreach (var item in resultItem.report.BotParams) { WriteItem(writer, item.Key, item.Value); } #endregion }
尽管将数据写入文件的方法很冗长,但它的实现非常简单。 创建相应分区并填充属性之后,该方法将数据添加到执行优化后的通关信息的 VaR,和表征最大利润和回撤的值。 还创建了一个嵌套函数,用于输出特定日期的优化结果,调用 5 次,每天一次。 之后,添加未分组的系数和根参数。 由于所述过程在一个循环中针对每个元素执行,因此只至调用 xmlWriter.Close() 方法之前,数据才被写入文件(这是在主要写入方法中完成的)。 因此,与先前研究的方法相比,这是输出数据数组的最快扩展方法。 我们已研究了将数据写入文件的有关过程。 现在我们进入论述的下一个逻辑环节,即从结果文件中读取数据。
读取优化报告文件
我们需要读取文件,以便处理接收到的信息,并显示它。 因此,需要相应的文件读取机制。 它作为一个单独的类实现:
public class ReportReader : IDisposable { /// <summary> /// Constructor /// </summary> /// <param name="path">Path to file</param> public ReportReader(string path); /// <summary> /// Binary number format provider /// </summary> private readonly NumberFormatInfo formatInfo = new NumberFormatInfo { NumberDecimalSeparator = "." }; #region DataKeepers /// <summary> /// Presenting the report file in OOP format /// </summary> private readonly XmlDocument document = new XmlDocument(); /// <summary> /// Collection of document nodes (rows in excel table) /// </summary> private readonly System.Collections.IEnumerator enumerator; #endregion /// <summary> /// The read current report item /// </summary> public ReportItem? ReportItem { get; private set; } = null; #region Optimiser settings /// <summary> /// Path to the robot /// </summary> public string RelativePathToBot { get; } /// <summary> /// Balance /// </summary> public double Balance { get; } /// <summary> /// Currency /// </summary> public string Currency { get; } /// <summary> /// Leverage /// </summary> public int Leverage { get; } #endregion /// <summary> /// File creation date /// </summary> public DateTime Created { get; } /// <summary> /// File reader method /// </summary> /// <returns></returns> public bool Read(); /// <summary> /// The method receiving the item by its name (the Name attribute) /// </summary> /// <param name="Name"></param> /// <returns></returns> private string SelectItem(string Name) => $"Item[@Name='{Name}']"; /// <summary> /// Get the trading result value for the selected day /// </summary> /// <param name="dailyNode">Node of this day</param> /// <returns></returns> private DailyData GetDay(XmlNode dailyNode); /// <summary> /// Reset the quote reader /// </summary> public void ResetReader(); /// <summary> /// Clear the document /// </summary> public void Dispose() => document.RemoveAll(); }
我们详细查看该结构。 该类自 iDisposable 接口继承而来。 这不是必需条件,这样做只是出于预防起见。 现在,所述类包含必需的 Dispasable 方法,该方法清除 document 对象。 该对象将优化结果文件存储到内存中。
这种方法很方便,因为在创建实例时,从上述接口继承的类应包装到 ‘using’ 构造,当超出 ‘using’ 结构模块的边界时,该构造将自动调用指定的方法。 这意味着读取的文档不会在内存中保留很长,因此减少了内存占用量。
逐行文档阅读器类利用 Enumerator 从读取文档里接收数据。 读取的值将写入 指定属性,因此我们提供了对数据的访问。 此外,在类实例化期间将填充以下数据:指定主要优化器设置,文件创建日期和时间的属性。 为了消除操作系统本地化设置的影响(在写入文件和读取文件时),要指明双精度数字的定界符格式。 首次读取文件时,应重置到列表开头。 为此,我们使用 ResetReader 方法将 Enumerator 重置到列表开头。 实现类构造函数是为了填充所有必需的属性,并为类的进一步运用做准备。
public ReportReader(string path) { // load the document document.Load(path); // Get file creation date Created = DateTime.ParseExact(document["Optimisation_Report"].Attributes["Created"].Value, "dd.MM.yyyy HH:mm:ss", null); // Get enumerator enumerator = document["Optimisation_Report"]["Optimisation_Results"].ChildNodes.GetEnumerator(); // Parameter receiving function string xpath(string Name) { return $"/Optimisation_Report/Optimiser_Settings/Item[@Name='{Name}']"; } // Get path to the robot RelativePathToBot = document.SelectSingleNode(xpath("Bot")).InnerText; // Get balance and deposit currency XmlNode Deposit = document.SelectSingleNode(xpath("Deposit")); Balance = Convert.ToDouble(Deposit.InnerText.Replace(",", "."), formatInfo); Currency = Deposit.Attributes["Currency"].Value; // Get leverage Leverage = Convert.ToInt32(document.SelectSingleNode(xpath("Leverage")).InnerText); }
首先,它加载所传递文档,并填写其创建日期。 在类实例化期间获得的 Enumerator 属于位于 Optimization_Report/Optimization_Results 分区下的文档子节点,即属于含有标签 <Result/> 的节点。 若要获得所需的优化器配置参数,需用 xpath 标记指定所需文档节点的路径。 这种含有较短路径的内置函数的模拟物是 SelectItem 方法,该方法根据其 Name 属性指示文档节点中含有标签 <Item/> 的某个数据项的路径。 GetDay 方法将所传递文档节点转换到每日交易报告的相应结构。 该类中的最后一个方法是数据读取器方法。 其简要形式的实现如下所示。
public bool Read() { if (enumerator == null) return false; // Read the next item bool ans = enumerator.MoveNext(); if (ans) { // Current node XmlNode result = (XmlNode)enumerator.Current; // current report item ReportItem = new ReportItem[...] // Fill the robot parameters foreach (XmlNode item in result.ChildNodes) { if (item.Name == "Item") ReportItem.Value.BotParams.Add(item.Attributes["Name"].Value, item.InnerText); } } return ans; }
隐藏代码部分包含优化报告实例化操作,并用读取的数据填充报告字段。 此操作包括类似的动作,其中将字符串格式转换为所需的格式。 进一步的循环逐行读取文件,并用读取的数据填充机器人参数。 仅在未取得完整文件行的情况下,才执行此操作。 该操作的结果是返回读行是否完毕的指示。 它还可以表示到达文件末尾。
优化报告的多因素过滤和排序
为了达成目标,我创建了两个枚举来指示排序方向(SortMethd 和 OrderBy)。 它们很相似,大概只需其一就足够了。 不过,为了分离过滤和排序方法,创建了两个枚举而非一个。 枚举的目的是表示升序或降序。 所传递数值的系数比率类型由标志指示。 目的是设置比较条件。
/// <summary> /// Filtering type /// </summary> [Flags] public enum CompareType { GraterThan = 1, // greater than LessThan = 2, // less than EqualTo = 4 // equal }
按系数类型进行数据过滤和排序的说明已在前述枚举 OrderBy 里讲述。 排序和筛选方法是作为继承自 IEnumerable<OptimisationResult> 接口的方法扩展集合实现的。 在筛选方法中,我们逐项检查每个系数是否满足指定标准,若其中任一个系数不符合标准,则拒绝该优化通关信息。 为了过滤数据,我们使用 IEnumerable 接口中包含的 Where 循环。 该方法实现如下。
/// <summary> /// Optimization filtering method /// </summary> /// <param name="results">Current collection</param> /// <param name="compareData">Collection of coefficients and filtering types</param> /// <returns>Filtered collection</returns> public static IEnumerable<OptimisationResult> FiltreOptimisations(this IEnumerable<OptimisationResult> results, IDictionary<SortBy, KeyValuePair<CompareType, double>> compareData) { // Result sorting function bool Compare(double _data, KeyValuePair<CompareType, double> compareParams) { // Comparison result bool ans = false; // Comparison for equality if (compareParams.Key.HasFlag(CompareType.EqualTo)) { ans = compareParams.Value == _data; } // Comparison for 'greater than current' if (!ans && compareParams.Key.HasFlag(CompareType.GraterThan)) { ans = _data > compareParams.Value; } // Comparison for 'less than current' if (!ans && compareParams.Key.HasFlag(CompareType.LessThan)) { ans = _data < compareParams.Value; } return ans; } // Sorting condition bool Sort(OptimisationResult x) { // Loop through passed sorting parameters foreach (var item in compareData) { // Compare the passed parameter with the current one if (!Compare(x.GetResult(item.Key), item.Value)) return false; } return true; } // Filtering return results.Where(x => Sort(x)); }
该方法内部实现了两个函数,每个函数执行其自己的数据过滤任务。 我们从最终函数开始查看它们:
- Compare — 其目的是拿方法中指定的值与所传递的以 KeyValuePair 表示的值进行比较。 除了大于/小于和相等比较之外,我们可能还需要检查其他条件。 为此目的,我们将借用标志。 标志是一个数位,而 int 字段可存储 8 个数位。 因此,我们最多可以在 int 字段里同时设置或删除 8 个标志。 可以顺序检查标志,而无需创建多个循环或庞大的条件,因此我们仅有三个条件。 甚至,在稍后将要研究的图形界面中,使用标记设置所需的比较参数也很方便。 我们顺序检查该函数中的标志,并检查数据是否与这些标志相对应。
- Sort: 与以前的方法不同,此方法旨在检查多个写入参数,而非一个。 我们运行逐项循环,遍历传递给过滤器的所有标志,并利用前述的函数来查找所选参数是否满足指定条件。 为了在循环中无需使用 “switc – case” 运算符即可访问特定选择项的值,用到了上述 OptimisationResult.GetResult(OrderBy item) 方法。 如果所传递的值与请求的值不匹配,则返回 false,并舍弃不合适的值。
‘Where’ 方法用于对数据排序。 它会自动生成相应条件的列表,并返回该扩展方法的执行结果。
数据过滤非常易于理解。 排序可能会遇到困难。 我们用一个示例来研究排序机制。 假设我们有盈利因子和回报因子参数。 我们需要按这两个参数对数据进行排序。 如果我们一个接一个地执行两次排序迭代,我们只会得到按最后一个参数排序的数据。 我们需要以某种方式比较这些值。
| 盈利 | 盈利因子 | 回报因子 |
|---|---|---|
| 5000 | 1 | 9 |
| 15000 | 1.2 | 5 |
| -11000 | 0.5 | -2 |
| 0 | 0 | 0 |
| 10000 | 2 | 5 |
| 7000 | 1 | 4 |
这两个系数在其边界值内未进行常规化。 另外它们彼此之间的数值范围也很宽。 逻辑上,我们首先需要将它们常规化,同时保留它们的顺序。 将数据转化为常规化形式的标准方法是将每个数据除以序列中的最大值:因此,我们将得到一系列在 [0;1] 范围内变动的数值。 但是首先,我们需要找出表中所示一系列数值的极值。
| 盈利因子 | 回报因子 | |
|---|---|---|
| 最小 | 0 | -2 |
| 最大 | 2 | 9 |
如表中所示,回报因子含负值,因此上述方法不适用于此。 为了消除这种影响,我们简单地将整个序列按负数值取模。 现在我们可以计算每个参数的常规化数值。
| 盈利 | 盈利因子 | 回报因子 | 常规化合计 |
|---|---|---|---|
| 5000 | 0.5 | 1 | 0.75 |
| 15000 | 0.6 | 0.64 | 0.62 |
| -11000 | 0.25 | 0 | 0.13 |
| 0 | 0 | 0.18 | 0.09 |
| 10000 | 1 | 0.64 | 0.82 |
| 7000 | 0.5 | 0.55 | 0.52 |
现在我们得到所有常规化形式的系数,我们可以使用加权合计,其中权重等于 1 除以 n(此处 n 是加权因子数量)。 结果则为,我们得到了可作为排序标准的常规化竖列。 如果任何系数应按降序排序,则需要从其一减去此参数,且因此交换最大和最小系数。
实现此机制的代码以两种方法呈现,第一种方法指示排序顺序(升序或降序),第二种方法实现排序机制。 第一个方法 SortMethod GetSortMethod(SortBy sortBy) 非常简单,因此我们进到第二个方法。
public static IEnumerable<OptimisationResult> SortOptimisations(this IEnumerable<OptimisationResult> results, OrderBy order, IEnumerable<SortBy> sortingFlags, Func<SortBy, SortMethod> sortMethod = null) { // Get the unique list of flags for sorting sortingFlags = sortingFlags.Distinct(); // Check flags if (sortingFlags.Count() == 0) return null; // If there is one flag, sort by this parameter if (sortingFlags.Count() == 1) { if (order == OrderBy.Ascending) return results.OrderBy(x => x.GetResult(sortingFlags.ElementAt(0))); else return results.OrderByDescending(x => x.GetResult(sortingFlags.ElementAt(0))); } // Form minimum and maximum boundaries according to the passed optimization flags Dictionary<SortBy, MinMax> Borders = sortingFlags.ToDictionary(x => x, x => new MinMax { Max = double.MinValue, Min = double.MaxValue }); #region create Borders min max dictionary // Loop through the list of optimization passes for (int i = 0; i < results.Count(); i++) { // Loop through sorting flags foreach (var item in sortingFlags) { // Get the value of the current coefficient double value = results.ElementAt(i).GetResult(item); MinMax mm = Borders[item]; // Set the minimum and maximum values mm.Max = Math.Max(mm.Max, value); mm.Min = Math.Min(mm.Min, value); Borders[item] = mm; } } #endregion // The weight of the weighted sum of normalized coefficients double coef = (1.0 / Borders.Count); // Convert the list of optimization results to the List type array // Since it is faster to work with List<OptimisationResult> listOfResults = results.ToList(); // Loop through optimization results for (int i = 0; i < listOfResults.Count; i++) { // Assign value to the current coefficient OptimisationResult data = listOfResults[i]; // Zero the current sorting factor data.SortBy = 0; // Loop through the formed maximum and minimum borders foreach (var item in Borders) { // Get the current result value double value = listOfResults[i].GetResult(item.Key); MinMax mm = item.Value; // If the minimum is below zero, shift all data by the negative minimum value if (mm.Min < 0) { value += Math.Abs(mm.Min); mm.Max += Math.Abs(mm.Min); } // If the maximum is greater than zero, calculate if (mm.Max > 0) { // Calculate the coefficient according to the sorting method if ((sortMethod == null ? GetSortMethod(item.Key) : sortMethod(item.Key)) == SortMethod.Decreasing) { // Calculate the coefficient to sort in descending order data.SortBy += (1 - value / mm.Max) * coef; } else { // Calculate the coefficient to sort in ascending order data.SortBy += value / mm.Max * coef; } } } // Replace the value of the current coefficient with the sorting parameter listOfResults[i] = data; } // Sort according to the passed sorting type if (order == OrderBy.Ascending) return listOfResults.OrderBy(x => x.SortBy); else return listOfResults.OrderByDescending(x => x.SortBy); }
如果只按一个参数执行排序,则执行排序无需序列的常规化。 然后立即返回结果。 如果要按若干个参数进行排序,我们首先生成一个字典,该字典由所该序列中的最大和最小值组成。 这样可以加快计算速度,因为不如此的话我们要在每次迭代期间请求参数。 这会产生远多于我们在此实现中想象的循环。
然后,为求加权合计形成权重,并执行将序列常规化的操作。 此处再次用到两个循环,上述操作在内循环中执行。 加权合计结果被添加到相应数组元素的 SortBy 变量当中。 在此操作结束时,用于排序的结果系数既已形成,通过标准 List<T>.OrderBy 或 List<T> 数组方法调用前述的排序方法。 OrderByDescending — 当需要降序排序时。 加权合计的单独成员的排序方法,通过传递给函数的参数之一 delegate 进行设置。如果将此委托保留为默认参数值,则使用前面提到的方法,否则使用所传递的委托。
结束语
我们已创建了一种机制,将来会在我们的应用程序中积极运用。 除了加载和读取自定义格式的 xml 文件(该文件存储有关已执行测试的结构化信息)之外,该机制还包含 C# 集合扩展方法,这些方法用于对数据进行排序和过滤。 我们已经实现了多因素排序机制,这在标准终端测试器中不曾提供。 排序方法的优点之一是能够参考一系列因素。 不过,其缺点是只能在给定系列中比较结果。 这意味着所选时间间隔的加权合计无法与其他间隔进行比较,因为它们当中的每一个都使用独立的系数序列。 在下一篇文章中,我们将研究算法转换方法,启用支持该算法的应用程序或自动优化器,以及创建这种自动优化器。
本文译自 MetaQuotes Software Corp. 撰写的俄文原文
原文地址: https://www.mql5.com/ru/articles/7290
MyFxtops迈投(www.myfxtops.com)-靠谱的外汇跟单社区,免费跟随高手做交易!
免责声明:本文系转载自网络,如有侵犯,请联系我们立即删除,另:本文仅代表作者个人观点,与迈投财经无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。