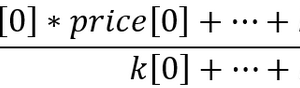总结
如果交易者试图吸引投资者,他们很可能会检查他或她的交易结果。所以交易者应该能够提供交易历史来显示结果。MetaTrader 5允许您将交易历史记录保存到一个文件中(工具箱-交易选项卡-关联菜单-报告)。报告可以保存为XLSX(在Microsoft Excel中分析)和HTML文件,可以在任何浏览器中查看。第二种选择显然更受欢迎,因为有些用户可能没有Excel,而且每个人都有浏览器。因此,具有交易结果的HTML报告更适合潜在投资者。
除了这些报告中提供的标准度量之外,您还可能希望使用从报告中提取的事务数据自行计算隐藏值。在本文中,我们将研究如何从HTML报告中提取数据。首先,我们将分析报表的结构,然后编写一个函数来解析它们。报告的名称将传递给函数。然后,函数返回包含相关数据的结构。此结构允许直接访问任何报表值。使用此结构,您可以根据任何所需的度量轻松快速地生成自己的报告。
除了交易报告外,MetaTrader 5还可以保存智能交易系统的测试和优化报告。与事务历史类似,测试报告可以保存为两种格式:XLSX和HTML,而优化报告可以保存为XML格式。
在本文中,我们将研究HTML测试报告、XML优化报告和HTML事务历史报告。
HTML和XML文件
HTML文件实际上是一个由文本(可显示数据)和标签组成的文本文件,这些文本文件指示如何显示数据(图例1)。所有标记都以字符“<;”开头,以“>;”结尾。例如,标签<;br>;表示其后续文本应以新行开头,而<;p>;表示文本应以新段落开头(不仅是新行,而且是空行之后)。其他属性可以放置在标记内,例如<;p color=“red”>;,这意味着标记后面的文本应以新段落开头,并以红色书写。nbsp;

的图例1在记事本中打开HTML文件片段
要取消标签操作,将使用一个闭合标签,该标签类似于起始标签,并且在开始处有一个斜线“/”。例如,<;/p>;是段落的封闭标签。某些标签在使用时不必被封闭,例如:有些标签可以选择性地使用封闭的标签。新段落可以在没有结束前一段的情况下开始。但是,如果在标签内使用颜色属性,如在上面的lt;p & gt的情况下,必须使用一个关闭的标签来取消将来的文本着色。某些标记需要关闭,例如<;table>;。表格应始终以闭合标签<;/table>;结尾,表格由<;tr>;开始和结束标签<;/tr>;和结束行组成。行中的单元格由<;td>;和<;/td>;定义,有时单元格使用<;th>;标签(标题单元格)。同一个表可能同时包含这两个单元格,即<;td>;标签和<;th>;标签单元格。行和单元格的关闭标签是必需的。
目前,大多数HTML属性实际上是未使用的。相反,它使用一个“style”属性来描述元素的外观。例如:<;p style=“color:red”>;表示红色的段落,但这不是非常流行的方法。最常见的方法是使用“class”属性,该属性仅指定样式类的名称,例如<;p class=“small”>;,而类本身(样式说明)位于HTML文档或单独的CSS文件(层叠样式表)的开头。nbsp;
XML文件(图2)与HTML非常相似。主要区别在于HTML支持严格限制的标记集,而XML允许扩展标记集和添加自定义标记。

图例2中在记事本中打开的XML文件片段
HTML的主要目的是显示数据,这就是为什么它有一组标准的标记。因为这个HTML文档在不同的浏览器中具有几乎相同的外观。XML的主要目的是保存和传输数据,因此支持任何数据结构的可能性非常重要。此文件的用户必须了解这样做的目的以及他们需要提取的数据。
字符串函数或正则表达式
通常,正则表达式用于从文本中提取数据。在代码库中,您可以找到正则表达式函数库来处理表达式。您还可以看到如何使用它们的说明:“交易者的正则表达式”。当然,正则表达式是解析文本数据的强大而方便的工具。如果您经常需要处理数据解析和执行不同的任务,那么您肯定需要使用正则表达式。
然而,正则表达式有一些缺点:在使用它们之前需要正确地研究它们。关于正则表达式的整个概念非常广泛。当你需要它们的时候,你不能指望通过查找来使用它们。你必须深入学习这一理论,掌握实践技能。我认为使用正则表达式所需的思维方式与解决常见编程任务所需的思维方式大不相同。即使有使用正则表达式的能力,当切换回使用正则表达式时也可能存在障碍。nbsp;
如果数据解析任务不复杂且不频繁,则可以使用标准字符串函数。or event,there is a view that string functions run faster.最有可能的是,速度取决于任务类型和应用正则表达式的条件。然而,字符串函数为数据解析任务提供了一个很好的解决方案。
在语言引用中可用的所有字符串函数中,我们只需要几个:Stringring()、StringSubstr()、StringReplace()。我们也可能需要一些非常简单的函数,如SrutLLN(),StringTrimLeft(),StringTrimRight()。
测试器报告
测试报告包含很多数据,所以我们将从头开始。这将使我们能够理解任务并处理可能出现的所有障碍。在创建本文时,我使用了带有默认参数的expertmacd ea测试报告(附在下面)。在浏览器中打开报告以查看我们正在处理的内容(图3)。

Legend 3 HTML格式测试报告,在浏览器中打开。红线蓝色文本显示主报告部分
报表数据分为几个部分:报表名称、参数、结果、图表、订单交易、合计。nbsp;nbsp;
每个浏览器都有一个查看页面代码的命令:右键单击页面以打开关联的菜单,然后选择“查看页面源”或类似命令。nbsp;
通过对源代码的直观检查,我们可以发现所有报表数据都排列在表中(<;table>;标记)。测试报告有两个表。第一个表包含常规数据:从报告名称到“平均持仓时间”的值,即到订单部分。第二个表包含订单、交易和最终存款状态的数据。“colspan”属性用于将不同类型的数据放入一个表中,该表将多个单元格合并在一起。常用参数的名称和值位于表的不同单元格中,有时位于同一行,有时位于不同的行中。
一个重要的时刻是“id”属性的可用性,它是标记的唯一标识符。ID值可用于查找包含所需数据的单元格。但是,不使用“id”属性。这就是我们通过计算行和单元格来查找参数的原因。例如,名称“policy tester report”位于第一个表、第一行和第一个单元格中。nbsp;
在所有报表中,第二张表中的订单和事务数量将有所不同,因此我们需要找到订单的结束和交易的开始。事务之后是一个单元行,接着是一个标题行——一个数据分离的指示。现在我们不再详细说明行和单元格的数目。稍后将介绍一种方便的方法。
所有数据都在表单元格中,所以在初始阶段我们需要做的是提取表、行和单元格。
让我们分析事务历史并优化报表。历史报告与测试报告非常相似,除了附加的最终存款状态部分(图4)。

以HTML格式显示的Legend 4交易历史记录报告,在浏览器中打开。红线蓝色文本显示主报告部分
通过检查事务历史记录的HTML代码,我们可以看到单元格不仅由<;td>;标记定义,而且由代表标题单元格的<;th>;定义。此外,所有数据都在一个表中。
优化报告非常简单——表中只有一个数据部分。从它的源代码中,我们可以看到它是用<;table>;标记创建的,行是用<;row>;创建的,单元格是用<;cell>;定义的,所有标记都是用相应的结束标记定义的。
文件加载
在我们处理报表数据之前,我们需要从文件中读取它们。我们使用以下函数将整个文件内容返回到字符串变量:
bool FileGetContent(string aFileName,string & aContent){ int h=FileOpen(aFileName,FILE_READ|FILE_TXT); if(h==-1)return(false); aContent=""; while(!FileIsEnding(h)){ aContent=aContent+FileReadString(h); } FileClose(h); return(true); }
传递给函数的第一个参数是报表文件的名称。第二个参数是包含文件内容的变量。函数根据结果返回真/假。
提取形式
我们使用两个结构来定位表数据。包含表行的结构:
struct Str{ string td[]; };
td[]数组的每个元素都将包含单元格的内容。
包含整个表(所有行)的结构:
struct STable{
Str tr[];
};
数据将从报告中提取如下:首先,我们需要找到表开始标记的起始位置。由于标记可能包含属性,因此我们只搜索开头的标记:“<;table”。在找到开始标记的开头之后,我们继续找到它的结尾,“>;”。然后搜索表单以一个封闭标签“<;/table>;”结尾。这很容易,因为报表不包含嵌套表,即每个开始标记后面都有一个关闭标记。
找到表后,我们对表行重复相同的操作,这次使用“<;tr”作为开始,使用“<;/tr”作为结束。然后,在每个表行中,我们将查找单元格,这次从“<;td”开始,以“<;/td>”结束。表行的任务有些复杂,因为单元格可以同时包含<;td>;和<;th>;标记。因此,我们将用自定义的tagfind()函数替换stringfind():
int TagFind(string aContent,string & aTags[],int aStart,string & aTag){ int rp=-1; for(int i=0;i<ArraySize(aTags);i++){ int p=StringFind(aContent,"<"+aTags[i],aStart); if(p!=-1){ if(rp==-1){ rp=p; aTag=aTags[i]; } else{ if(p<rp){ rp=p; aTag=aTags[i]; } } } } return(rp); }
功能参数:
- 字符串内容-要搜索的字符串;
- string&atags[]-存储标记数组;
- int astart-搜索的起始位置;
- string&atag-找到的标记通过引用返回。
与stringfind()不同,数组被传递给tagfind()函数,而不是要搜索的字符串。开始的“<;”将添加到函数的搜索字符串中。此函数返回最近标记的位置。
使用tagfind(),我们将始终搜索开始和结束标记。它们之间找到的所有内容将被收集到一个数组中:
int TagsToArray(string aContent,string & aTags[],string & aArray[]){ ArrayResize(aArray,0); int e,s=0; string tag; while((s=TagFind(aContent,aTags,s,tag))!=-1 && !IsStopped()){ s=StringFind(aContent,">",s); if(s==-1)break; s++; e=StringFind(aContent,"</"+tag,s); if(e==-1)break; ArrayResize(aArray,ArraySize(aArray)+1); aArray[ArraySize(aArray)-1]=StringSubstr(aContent,s,e-s); } return(ArraySize(aArray)); }
功能参数:
- 字符串内容-要搜索的字符串;
- string&atags[]-存储标记数组;
- 字符串aReal[]-返回包含所有找到的标签内容的数组的引用。
只有在解析单元格时,搜索到的标签数组才会传递给TagsToArray()。这就是为什么,对于所有其他情况,我们将使用通常的字符串参数来编写函数模拟:
int TagsToArray(string aContent,string aTag,string & aArray[]){ string Tags[1]; Tags[0]=aTag; return(TagsToArray(aContent,Tags,aArray)); }
功能参数:
- 字符串Actrunt-我们要搜索的字符串;
- String和AtAG搜索标签;
- 字符串aReal[]-返回包含所有找到的标签内容的数组的引用。
现在我们继续提炼提取表内容的功能。将包含已分析文件名的字符串参数afilename传递给函数。函数中使用本地字符串变量保存文件内容,使用本地数组保存稳定结构:
STable tables[];
string FileContent;
使用filegetContent函数获取整个报告内容:
if(!FileGetContent(aFileName,FileContent)){ return(true); }
这是一个辅助变量:
string tags[]={"td","th"}; string ttmp[],trtmp[],tdtmp[]; int tcnt,trcnt,tdcnt;
“tags”数组中提供了单元格标签的可能选项。表、行和单元格的内容分别放置在临时字符串数组ttmp[]、trtmp[]和tdtmp[]中。nbsp;
从表中检索数据:
tcnt=TagsToArray(FileContent,"table",ttmp); ArrayResize(tables,tcnt);
循环遍历所有表并提取行,然后从行中提取单元格:
for(int i=0;i<tcnt;i++){ trcnt=TagsToArray(ttmp[i],"tr",trtmp); ArrayResize(tables[i].tr,trcnt); for(int j=0;j<trcnt;j++){ tdcnt=TagsToArray(trtmp[j],tags,tdtmp); ArrayResize(tables[i].tr[j].td,tdcnt); for(int k=0;k<tdcnt;k++){ tables[i].tr[j].td[k]=RemoveTags(tdtmp[k]); } } }
首先接收表、行和单元格,并将它们保存到临时数组中,然后将单元格数组复制到结构中。在复制过程中,细胞被removeTags()函数过滤。表格单元格可以有嵌套标签。removeTags()删除它们,只留下必要的标记。
拆卸气囊()功能:
string RemoveTags(string aStr){ string rstr=""; int e,s=0; while((e=StringFind(aStr,"<",s))!=-1){ if(e>s){ rstr=rstr+StringSubstr(aStr,s,e-s); } s=StringFind(aStr,">",e); if(s==-1)break; s++; } if(s!=-1){ rstr=rstr+StringSubstr(aStr,s,StringLen(aStr)-s); } StringReplace(rstr," "," "); while(StringReplace(rstr," "," ")>0); StringTrimLeft(rstr); StringTrimRight(rstr); return(rstr); }
让我们看看removeTags()函数。“s”变量位于所用数据的开头。它的数据首先等于零,因为数据可以从行的开头开始。在“while”循环中搜索开始括号“<;”,表示标记的开始。找到起始标记后,所有数据都将从s变量指定的位置复制到rstr变量,并复制到关键字的位置。然后,搜索标记的结尾是下一个有效数据的开始。循环之后,如果“s”变量的值不等于-1(这意味着字符串以有效数据结束,但尚未复制),则数据将复制到“rstr”变量。在函数末尾,空格指示符替换为简单的空格,同时删除字符串开头和结尾的重复空格和空格。
在这一步中,我们的“tables”数组结构是用纯表数据填充的。我们将这个数组保存到一个文本文件中。保存时,我们设置表、行和单元格的数目(保存到文件1.txt的数据):
int h=FileOpen("1.txt",FILE_TXT|FILE_WRITE); for(int i=0;i<ArraySize(tables);i++){ FileWriteString(h,"table "+(string)i+"/n"); for(int j=0;j<ArraySize(tables[i].tr);j++){ FileWriteString(h," tr "+(string)j+"/n"); for(int k=0;k<ArraySize(tables[i].tr[j].td);k++){ FileWriteString(h," td "+(string)k+": "+tables[i].tr[j].td[k]+"/n"); } } } FileClose(h);
通过这个文件,我们可以很容易地理解数据所在的单元。以下是文件片段:
table 0 tr 0 td 0: Strategy Test report tr 1 td 0: IMPACT-Demo (Build 1940) tr 2 td 0: tr 3 td 0: Settings tr 4 td 0: Expert Advisor: td 1: ExpertMACD tr 5 td 0: Symbol: td 1: USDCHF tr 6 td 0: Period: td 1: H1 (2018.11.01 - 2018.12.01) tr 7 td 0: Parameters: td 1: Inp_Expert_Title=ExpertMACD tr 8 td 0: td 1: Inp_Signal_MACD_PeriodFast=12 tr 9 td 0: td 1: Inp_Signal_MACD_PeriodSlow=24 tr 10 td 0: td 1: Inp_Signal_MACD_PeriodSignal=9 tr 11
报告数据结构
现在我们有一些无聊的例程:我们需要编写一个与报表数据对应的结构,并用表数组中的数据填充它。报告分为几个部分。因此,我们将使用几个结构来形成一个通用结构。
设置部分的结构:
struct SSettings{ string Expert; string Symbol; string Period; string Inputs; string Broker; string Currency; string InitialDeposit; string Leverage; };
结构域的目的顾名思义。结构的所有字段都包含与报告中显示的数据完全相同的数据。智能交易系统的参数列表将位于一个字符串变量“输入”中。
结果数据部分的结构:
struct SResults{ string HistoryQuality; string Bars; string Ticks; string Symbols; string TotalNetProfit; string BalanceDrawdownAbsolute; string EquityDrawdownAbsolute; string GrossProfit; string BalanceDrawdownMaximal; string EquityDrawdownMaximal; string GrossLoss; string BalanceDrawdownRelative; string EquityDrawdownRelative; string ProfitFactor; string ExpectedPayoff; string MarginLevel; string RecoveryFactor; string SharpeRatio; string ZScore; string AHPR; string LRCorrelation; string OnTesterResult; string GHPR; string LRStandardError; string TotalTrades; string ShortTrades_won_pers; string LongTrades_won_perc; string TotalDeals; string ProfitTrades_perc_of_total; string LossTrades_perc_of_total; string LargestProfitTrade; string LargestLossTrade; string AverageProfitTrade; string AverageLossTrade; string MaximumConsecutiveWins_cur; string MaximumConsecutiveLosses_cur; string MaximalConsecutiveProfit_count; string MaximalConsecutiveLoss_count; string AverageConsecutiveWins; string AverageConsecutiveLosses; string Correlation_Profits_MFE; string Correlation_Profits_MAE; string Correlation_MFE_MAE; string MinimalPositionHoldingTime; string MaximalPositionHoldingTime; string AveragePositionHoldingTime; };
单个订单的数据结构:
struct SOrder{ string OpenTime; string Order; string Symbol; string Type; string Volume; string Price; string SL; string TP; string Time; string State; string Comment; };
单笔交易的数据结构:
struct SDeal{ string Time; string Deal; string Symbol; string Type; string Direction; string Volume; string Price; string Order; string Commission; string Swap; string Profit; string Balance; string Comment; };
最终存款状态的结构:
struct SSummary{ string Commission; string Swap; string Profit; string Balance; };
一般结构:
struct STestingReport{
SSettings Settings;
SResults Results;
SOrder Orders[];
SDeal Deals[];
SSummary Summary;
};
sorder和deals结构数组用于订单和交易。
用数据填充结构
这项日常工作也需要注意。查看包含以前收到的表单数据的文本文件并填写结构:
aTestingReport.Settings.Expert=tables[0].tr[4].td[1]; aTestingReport.Settings.Symbol=tables[0].tr[5].td[1]; aTestingReport.Settings.Period=tables[0].tr[6].td[1]; aTestingReport.Settings.Inputs=tables[0].tr[7].td[1];
在上面的代码示例的最后一行中,一个值被分配给输入字段,但是该字段将只存储一个数据参数。然后收集其他参数。这些参数的位置从第8行开始,并且每个参数行中的第一个单元格为空。只要行中的第一个单元格为空,循环就会执行:
int i=8; while(i<ArraySize(tables[0].tr) && tables[0].tr[i].td[0]==""){ aTestingReport.Settings.Inputs=aTestingReport.Settings.Inputs+", "+tables[0].tr[i].td[1]; i++; }
以下是完整的测试报告分析功能:
bool TestingHTMLReportToStruct(string aFileName,STestingReport & aTestingReport){ STable tables[]; string FileContent; if(!FileGetContent(aFileName,FileContent)){ return(true); } string tags[]={"td","th"}; string ttmp[],trtmp[],tdtmp[]; int tcnt,trcnt,tdcnt; tcnt=TagsToArray(FileContent,"table",ttmp); ArrayResize(tables,tcnt); for(int i=0;i<tcnt;i++){ trcnt=TagsToArray(ttmp[i],"tr",trtmp); ArrayResize(tables[i].tr,trcnt); for(int j=0;j<trcnt;j++){ tdcnt=TagsToArray(trtmp[j],tags,tdtmp); ArrayResize(tables[i].tr[j].td,tdcnt); for(int k=0;k<tdcnt;k++){ tables[i].tr[j].td[k]=RemoveTags(tdtmp[k]); } } } // 设置部分 aTestingReport.Settings.Expert=tables[0].tr[4].td[1]; aTestingReport.Settings.Symbol=tables[0].tr[5].td[1]; aTestingReport.Settings.Period=tables[0].tr[6].td[1]; aTestingReport.Settings.Inputs=tables[0].tr[7].td[1]; int i=8; while(i<ArraySize(tables[0].tr) && tables[0].tr[i].td[0]==""){ aTestingReport.Settings.Inputs=aTestingReport.Settings.Inputs+", "+tables[0].tr[i].td[1]; i++; } aTestingReport.Settings.Broker=tables[0].tr[i++].td[1]; aTestingReport.Settings.Currency=tables[0].tr[i++].td[1]; aTestingReport.Settings.InitialDeposit=tables[0].tr[i++].td[1]; aTestingReport.Settings.Leverage=tables[0].tr[i++].td[1]; // 结果部分 i+=2; aTestingReport.Results.HistoryQuality=tables[0].tr[i++].td[1]; aTestingReport.Results.Bars=tables[0].tr[i].td[1]; aTestingReport.Results.Ticks=tables[0].tr[i].td[3]; aTestingReport.Results.Symbols=tables[0].tr[i].td[5]; i++; aTestingReport.Results.TotalNetProfit=tables[0].tr[i].td[1]; aTestingReport.Results.BalanceDrawdownAbsolute=tables[0].tr[i].td[3]; aTestingReport.Results.EquityDrawdownAbsolute=tables[0].tr[i].td[5]; i++; aTestingReport.Results.GrossProfit=tables[0].tr[i].td[1]; aTestingReport.Results.BalanceDrawdownMaximal=tables[0].tr[i].td[3]; aTestingReport.Results.EquityDrawdownMaximal=tables[0].tr[i].td[5]; i++; aTestingReport.Results.GrossLoss=tables[0].tr[i].td[1]; aTestingReport.Results.BalanceDrawdownRelative=tables[0].tr[i].td[3]; aTestingReport.Results.EquityDrawdownRelative=tables[0].tr[i].td[5]; i+=2; aTestingReport.Results.ProfitFactor=tables[0].tr[i].td[1]; aTestingReport.Results.ExpectedPayoff=tables[0].tr[i].td[3]; aTestingReport.Results.MarginLevel=tables[0].tr[i].td[5]; i++; aTestingReport.Results.RecoveryFactor=tables[0].tr[i].td[1]; aTestingReport.Results.SharpeRatio=tables[0].tr[i].td[3]; aTestingReport.Results.ZScore=tables[0].tr[i].td[5]; i++; aTestingReport.Results.AHPR=tables[0].tr[i].td[1]; aTestingReport.Results.LRCorrelation=tables[0].tr[i].td[3]; aTestingReport.Results.tables[0].tr[i].td[5]; i++; aTestingReport.Results.GHPR=tables[0].tr[i].td[1]; aTestingReport.Results.LRStandardError=tables[0].tr[i].td[3]; i+=2; aTestingReport.Results.TotalTrades=tables[0].tr[i].td[1]; aTestingReport.Results.ShortTrades_won_pers=tables[0].tr[i].td[3]; aTestingReport.Results.LongTrades_won_perc=tables[0].tr[i].td[5]; i++; aTestingReport.Results.TotalDeals=tables[0].tr[i].td[1]; aTestingReport.Results.ProfitTrades_perc_of_total=tables[0].tr[i].td[3]; aTestingReport.Results.LossTrades_perc_of_total=tables[0].tr[i].td[5]; i++; aTestingReport.Results.LargestProfitTrade=tables[0].tr[i].td[2]; aTestingReport.Results.LargestLossTrade=tables[0].tr[i].td[4]; i++; aTestingReport.Results.AverageProfitTrade=tables[0].tr[i].td[2]; aTestingReport.Results.AverageLossTrade=tables[0].tr[i].td[4]; i++; aTestingReport.Results.MaximumConsecutiveWins_cur=tables[0].tr[i].td[2]; aTestingReport.Results.MaximumConsecutiveLosses_cur=tables[0].tr[i].td[4]; i++; aTestingReport.Results.MaximalConsecutiveProfit_count=tables[0].tr[i].td[2]; aTestingReport.Results.MaximalConsecutiveLoss_count=tables[0].tr[i].td[4]; i++; aTestingReport.Results.AverageConsecutiveWins=tables[0].tr[i].td[2]; aTestingReport.Results.AverageConsecutiveLosses=tables[0].tr[i].td[4]; i+=6; aTestingReport.Results.Correlation_Profits_MFE=tables[0].tr[i].td[1]; aTestingReport.Results.Correlation_Profits_MAE=tables[0].tr[i].td[3]; aTestingReport.Results.Correlation_MFE_MAE=tables[0].tr[i].td[5]; i+=3; aTestingReport.Results.MinimalPositionHoldingTime=tables[0].tr[i].td[1]; aTestingReport.Results.MaximalPositionHoldingTime=tables[0].tr[i].td[3]; aTestingReport.Results.AveragePositionHoldingTime=tables[0].tr[i].td[5]; // 订单 ArrayFree(aTestingReport.Orders); int ocnt=0; for(i=3;i<ArraySize(tables[1].tr);i++){ if(ArraySize(tables[1].tr[i].td)==1){ break; } ArrayResize(aTestingReport.Orders,ocnt+1); aTestingReport.Orders[ocnt].OpenTime=tables[1].tr[i].td[0]; aTestingReport.Orders[ocnt].Order=tables[1].tr[i].td[1]; aTestingReport.Orders[ocnt].Symbol=tables[1].tr[i].td[2]; aTestingReport.Orders[ocnt].Type=tables[1].tr[i].td[3]; aTestingReport.Orders[ocnt].Volume=tables[1].tr[i].td[4]; aTestingReport.Orders[ocnt].Price=tables[1].tr[i].td[5]; aTestingReport.Orders[ocnt].SL=tables[1].tr[i].td[6]; aTestingReport.Orders[ocnt].TP=tables[1].tr[i].td[7]; aTestingReport.Orders[ocnt].Time=tables[1].tr[i].td[8]; aTestingReport.Orders[ocnt].State=tables[1].tr[i].td[9]; aTestingReport.Orders[ocnt].Comment=tables[1].tr[i].td[10]; ocnt++; } // 成交 i+=3; ArrayFree(aTestingReport.Deals); int dcnt=0; for(;i<ArraySize(tables[1].tr);i++){ if(ArraySize(tables[1].tr[i].td)!=13){ if(ArraySize(tables[1].tr[i].td)==6){ aTestingReport.Summary.Commission=tables[1].tr[i].td[1]; aTestingReport.Summary.Swap=tables[1].tr[i].td[2]; aTestingReport.Summary.Profit=tables[1].tr[i].td[3]; aTestingReport.Summary.Balance=tables[1].tr[i].td[4]; } break; } ArrayResize(aTestingReport.Deals,dcnt+1); aTestingReport.Deals[dcnt].Time=tables[1].tr[i].td[0]; aTestingReport.Deals[dcnt].Deal=tables[1].tr[i].td[1]; aTestingReport.Deals[dcnt].Symbol=tables[1].tr[i].td[2]; aTestingReport.Deals[dcnt].Type=tables[1].tr[i].td[3]; aTestingReport.Deals[dcnt].Direction=tables[1].tr[i].td[4]; aTestingReport.Deals[dcnt].Volume=tables[1].tr[i].td[5]; aTestingReport.Deals[dcnt].Price=tables[1].tr[i].td[6]; aTestingReport.Deals[dcnt].Order=tables[1].tr[i].td[7]; aTestingReport.Deals[dcnt].Commission=tables[1].tr[i].td[8]; aTestingReport.Deals[dcnt].Swap=tables[1].tr[i].td[9]; aTestingReport.Deals[dcnt].Profit=tables[1].tr[i].td[10]; aTestingReport.Deals[dcnt].Balance=tables[1].tr[i].td[11]; aTestingReport.Deals[dcnt].Comment=tables[1].tr[i].td[12]; dcnt++; } return(true); }
报告文件的名称将传递给函数。此函数中要填充的测试报告结构也通过引用传递。
请注意以“订单”和“交易”开头的注释代码部分。定义了订单列表开头的行号,而订单列表末尾基于检测包含单个单元格的行:
if(ArraySize(tables[1].tr[i].td)==1){ break; }
订单后将跳过三行:
// 成交 i+=3;
然后收集交易数据。交易记录列表的结尾由一行六个单元格决定-该行包含有关最终存款状态的数据。退出周期前填写最终存款状态的结构:
if(ArraySize(tables[1].tr[i].td)!=13){ if(ArraySize(tables[1].tr[i].td)==6){ aTestingReport.Summary.Commission=tables[1].tr[i].td[1]; aTestingReport.Summary.Swap=tables[1].tr[i].td[2]; aTestingReport.Summary.Profit=tables[1].tr[i].td[3]; aTestingReport.Summary.Balance=tables[1].tr[i].td[4]; } break; }
包含报告数据的结构已完全准备好。
交易历史报告
尽管最终的数据结构和结构的内容会有所不同,但可以将事务历史报告解析为Strategy Tester报告:
struct SHistory{
SHistoryInfo Info;
SOrder Orders[];
SDeal Deals[];
SSummary Summary;
SDeposit Deposit;
SHistoryResults Results;
};
Shistory结构包括以下结构:Shistory信息-一般账户信息、包含订单和交易数据结构的数组、Summary-交易结果、SDeposit-最终存款状态、Shistory结果-一般编号(利润、交易编号、取款等)。
用于分析事务报告的完整历史html reporttostruct()函数代码附在下面。向函数传递两个参数:
- 字符串文件名——报表文件的名称
- 史前历史-填写交易报告的数据结构
优化报告
优化报告的第一个区别是不同的文件类型。报告以ANSI格式保存,因此我们将使用另一个函数来读取其内容:
bool FileGetContentAnsi(string aFileName,string & aContent){ int h=FileOpen(aFileName,FILE_READ|FILE_TXT|FILE_ANSI); if(h==-1)return(false); aContent=""; while(!FileIsEnding(h)){ aContent=aContent+FileReadString(h); } FileClose(h); return(true); }
另一个区别是标签。<;table>;、<;tr>;和<;td>;将替换为以下标记:<;table>;、<;row>;和<;cell>;。最后一个主要差异与数据结构相关:
struct SOptimization{ string ParameterName[]; SPass Pass[]; };
结构由包含要优化参数名称的字符串数组(最右边的报告列)和传递结构数组组成:
struct SPass{ string Pass; string Result; string Profit; string ExpectedPayoff; string ProfitFactor; string RecoveryFactor; string SharpeRatio; string Custom; string EquityDD_perc; string Trades; string Parameters[]; };
此结构包括报表列中包含的字段。最后一个字段是字符串数组,它包含要优化的相应参数值,这取决于参数名称()数组中的名称。
下面将附上解析优化报告的优化器XMLRePotoStutt()函数的完整代码。两个参数传递给函数:
- 字符串文件名–报告文件的名称
- Soptimeization优化-要填充优化报表数据的结构
辅助函数
如果我们将本文中创建的所有结构和函数安排在一个包含文件中,那么报告解析将在三行代码中实现。nbsp;
1。包含文件:
#include <HTMLReport.mqh>
2。声明结构:
SHistory History;
三。调用函数:
HistoryHTMLReportToStruct("ReportHistory-555849.html",History);
之后,所有报表数据将以与报表排列完全相同的方式定位在相应的结构字段中。尽管所有字段都是字符串类型,但它们可以很容易地用于计算。为此,我们只需要将字符串转换为数字。但是,一些报告字段和相应的结构字段包含两个值。例如,订单量写在两个值“0.1/0.1”中,第一个值是订单量,第二个值是填充的量。有些总计在括号中也有双值、主值和附加值。例如,交易数量可以写为“11(54.55%)”—实际数量和相对百分比值。因此,我们需要编写辅助函数来简化这些值的使用。
提取单个交易量值的函数:
string Volume1(string aStr){ int p=StringFind(aStr,"/",0); if(p!=-1){ aStr=StringSubstr(aStr,0,p); } StringTrimLeft(aStr); StringTrimRight(aStr); return(aStr); } string Volume2(string aStr){ int p=StringFind(aStr,"/",0); if(p!=-1){ aStr=StringSubstr(aStr,p+1); } StringTrimLeft(aStr); StringTrimRight(aStr); return(aStr); }
volume 1()函数从类似于“0.1/0.1”的字符串中提取第一个事务值,volume 2()提取第二个值。
提取双数据的功能:
string Value1(string aStr){ int p=StringFind(aStr,"(",0); if(p!=-1){ aStr=StringSubstr(aStr,0,p); } StringTrimLeft(aStr); StringTrimRight(aStr); return(aStr); } string Value2(string aStr){ int p=StringFind(aStr,"(",0); if(p!=-1){ aStr=StringSubstr(aStr,p+1); } StringReplace(aStr,")",""); StringReplace(aStr,"%",""); StringTrimLeft(aStr); StringTrimRight(aStr); return(aStr); }
value1()函数从“8.02(0.08%)”类型的字符串中提取第一个值,value2()提取第二个值,并删除右括号和百分比标记(如果有)。
可能需要的另一个有用功能是测试报告结构的参数化数据转换。我们将使用以下结构将其转换为方便的形式:
struct SInput{ string Name, string Value; }
名称字段用于参数名称,值用于其值。数值类型是预先知道的,这就是为什么值字段具有字符串类型的原因。
以下函数将参数字符串转换为sinputs结构数组:
void InputsToStruct(string aStr,SInput & aInputs[]){ string tmp[]; string tmp2[]; StringSplit(aStr,',',tmp); int sz=ArraySize(tmp); ArrayResize(aInputs,sz); for(int i=0;i<sz;i++){ StringSplit(tmp[i],'=',tmp2); StringTrimLeft(tmp2[0]); StringTrimRight(tmp2[0]); aInputs[i].Name=tmp2[0]; if(ArraySize(tmp2)>1){ StringTrimLeft(tmp2[1]); StringTrimRight(tmp2[1]); aInputs[i].Value=tmp2[1]; } else{ aInputs[i].Value=""; } } }
参数字符串被拆分为带有“,”字符的数组。然后,将结果数组的每个元素分为一个名称和一个字符为“=”的值。
现在,所有准备工作都已就绪,可以分析提取的数据并生成定制报告。
创建自定义报表
现在我们可以访问报表数据,并且可以以任何首选的方式对其进行分析。有很多选择。利用交易结果,我们可以计算出一般的度量,如锐度比、恢复系数等。自定义HTML报表可以访问所有HTML、CSS和JavaScript函数。使用HTML,我们可以重新排列报告。例如,我们可以创建订单和交易表单,或者买卖单独的表单和其他类型的报告。
CSS支持数据着色,使报表更易于分析。javascript有助于使报表交互。例如,将鼠标悬停在事务行上会突出显示订单表单中相应的订单行。您可以生成图像并将其添加到HTML报告中。或者,javascript允许您直接在HTML5的canvas元素中绘制图像。这完全取决于你的需求、想象力和技能。
我们需要1创建一个自定义的HTML事务报告。我们将订单和交易合并到一个表中。取消的订单将以灰色显示,因为它们不提供感兴趣的信息。灰色也将用于市场价格订单,因为它们提供的信息与订单被执行后的结果相同。The deal will be highlighted in bright colors:blue and red.表格也应该有突出的颜色,如粉红色和蓝色。nbsp;
自定义报告表单将在订单和提交表单中包含标题。让我们准备对应的数组:
string TableHeader[]={ "Time", "Order", "Deal", "Symbol", "Type", "Direction", "Volume", "Price", "Order", "S/L", "T/P", "Time", "State", "Commission", "Swap", "Profit", "Balance", "Comment"};
我们收到包含报告数据的结构:
SHistory History;
HistoryHTMLReportToStruct("ReportHistory-555849.html",History);
我们打开生成报告的文件,并编写由htmlstart()函数形成的HTML页面的标准开头:
int h=FileOpen("Report.htm",FILE_WRITE); if(h==-1)return; FileWriteString(h,HTMLStart("Report")); FileWriteString(h,"<table>/n"); FileWriteString(h,"/t<tr>/n"); for(int i=0;i<ArraySize(TableHeader);i++){ FileWriteString(h,"/t/t<th>"+TableHeader[i]+"</th>/n"); } FileWriteString(h,"/t</tr>/n");
htmlstart()功能代码如下:
string HTMLStart(string aTitle,string aCSSFile="style.css"){ string str="<!DOCTYPE html>/n"; str=str+"<html>/n"; str=str+"<head>/n"; str=str+"<link href=/""+aCSSFile+"/" rel=/"stylesheet/" type=/"text/css/">/n"; str=str+"<title>"+aTitle+"</title>/n"; str=str+"</head>/n"; str=str+"<body>/n"; return str; }
带有标记的页面标题和带有样式的文件名的字符串将传递给函数。
遍历所有订单,定义字符串显示类型并形成:
int j=0; for(int i=0;i<ArraySize(History.Orders);i++){ string sc=""; if(History.Orders[i].State=="canceled"){ sc="PendingCancelled"; } else if(History.Orders[i].State=="filled"){ if(History.Orders[i].Type=="buy"){ sc="OrderMarketBuy"; } else if(History.Orders[i].Type=="sell"){ sc="OrderMarketSell"; } if(History.Orders[i].Type=="buy limit" || History.Orders[i].Type=="buy stop"){ sc="OrderPendingBuy"; } else if(History.Orders[i].Type=="sell limit" || History.Orders[i].Type=="sell stop"){ sc="OrderMarketSell"; } } FileWriteString(h,"/t<tr class=/""+sc+"/">/n"); FileWriteString(h,"/t/t<td>"+History.Orders[i].OpenTime+"</td>/n"); // 时间 FileWriteString(h,"/t/t<td>"+History.Orders[i].Order+"</td>/n"); // 订单 FileWriteString(h,"/t/t<td>"+" "+"</td>/n"); // 成交 FileWriteString(h,"/t/t<td>"+History.Orders[i].Symbol+"</td>/n"); // 品种 FileWriteString(h,"/t/t<td>"+History.Orders[i].Type+"</td>/n"); // 类型 FileWriteString(h,"/t/t<td>"+" "+"</td>/n"); // 方向 FileWriteString(h,"/t/t<td>"+History.Orders[i].Volume+"</td>/n"); // 成交量 FileWriteString(h,"/t/t<td>"+History.Orders[i].Price+"</td>/n"); // 价格 FileWriteString(h,"/t/t<td>"+" "+"</td>/n"); // 订单 FileWriteString(h,"/t/t<td>"+History.Orders[i].SL+"</td>/n"); // 止损 FileWriteString(h,"/t/t<td>"+History.Orders[i].TP+"</td>/n"); // 止盈 FileWriteString(h,"/t/t<td>"+History.Orders[i].Time+"</td>/n"); // 时间 FileWriteString(h,"/t/t<td>"+History.Orders[i].State+"</td>/n"); // 状态 FileWriteString(h,"/t/t<td>"+" "+"</td>/n"); // 佣金 FileWriteString(h,"/t/t<td>"+" "+"</td>/n"); // 掉期利率 FileWriteString(h,"/t/t<td>"+" "+"</td>/n"); // 盈利 FileWriteString(h,"/t/t<td>"+" "+"</td>/n"); // 余额 FileWriteString(h,"/t/t<td>"+History.Orders[i].Comment+"</td>/n"); // 注释 FileWriteString(h,"/t</tr>/n");
如果订单已填写,则找到相应的交易,定义显示样式并形成HTML代码:
// 查找一笔成交 if(History.Orders[i].State=="filled"){ for(;j<ArraySize(History.Deals);j++){ if(History.Deals[j].Order==History.Orders[i].Order){ sc=""; if(History.Deals[j].Type=="buy"){ sc="DealBuy"; } else if(History.Deals[j].Type=="sell"){ sc="DealSell"; } FileWriteString(h,"/t<tr class=/""+sc+"/">/n"); FileWriteString(h,"/t/t<td>"+History.Deals[j].Time+"</td>/n"); // 时间 FileWriteString(h,"/t/t<td>"+" "+"</td>/n"); // 订单 FileWriteString(h,"/t/t<td>"+History.Deals[j].Deal+"</td>/n"); // 成交 FileWriteString(h,"/t/t<td>"+History.Deals[j].Symbol+"</td>/n"); // 品种 FileWriteString(h,"/t/t<td>"+History.Deals[j].Type+"</td>/n"); // 类型 FileWriteString(h,"/t/t<td>"+History.Deals[j].Direction+"</td>/n"); // 方向 FileWriteString(h,"/t/t<td>"+History.Deals[j].Volume+"</td>/n"); // 成交量 FileWriteString(h,"/t/t<td>"+History.Deals[j].Price+"</td>/n"); // 价格 FileWriteString(h,"/t/t<td>"+History.Deals[j].Order+"</td>/n"); // 订单 FileWriteString(h,"/t/t<td>"+" "+"</td>/n"); // 止损 FileWriteString(h,"/t/t<td>"+" "+"</td>/n"); // 止盈 FileWriteString(h,"/t/t<td>"+" "+"</td>/n"); // 时间 FileWriteString(h,"/t/t<td>"+" "+"</td>/n"); // 状态 FileWriteString(h,"/t/t<td>"+History.Deals[j].Commission+"</td>/n"); // 佣金 FileWriteString(h,"/t/t<td>"+History.Deals[j].Swap+"</td>/n"); // 掉期利率 FileWriteString(h,"/t/t<td>"+History.Deals[j].Profit+"</td>/n"); // 盈利 FileWriteString(h,"/t/t<td>"+History.Deals[j].Balance+"</td>/n"); // 余额 FileWriteString(h,"/t/t<td>"+History.Deals[j].Comment+"</td>/n"); // 注释 FileWriteString(h,"/t</tr>/n"); break; } } }
然后,我们关闭该表并添加标准HTML页面的结尾,该页面由html end()函数构成:
FileWriteString(h,"</table>/n"); FileWriteString(h,HTMLEnd("Report"));
htmlend()功能代码:
string HTMLEnd(){
string str="</body>/n";
str=str+"</html>/n";
return str;
}
现在我们只需要编写样式文件样式。CSS。学习CSS超出了本文的范围,因此我们不会对此进行详细研究。您可以看到下面的附加文件。附件还包含用于创建报表的脚本-htmlreportcreate。MQ5。
这是一份现成的报告:
图例5自定义HTML报告片段
结束语
您可能想知道正则表达式是否更容易使用。总体结构和原则相同。我们将收到一个表内容数组,后面是行和单元格。我们将用包含正则表达式的函数替换TagsToArray()。其余的将非常相似。
本文中描述的创建自定义报表的示例只是显示报表的选项之一。这只是一个例子。您可以使用自己容易理解的表单。这篇文章最重要的结果是,您可以轻松访问所有报表数据。
圈地
- 包括/htmlreport。mqh-包含报告解析函数的文件。
- scripts/htmlreporttest.mq5-使用htmlreport.mqh分析测试、优化和历史报告的示例。
- scripts/html report create.mq5-创建自定义HTML报告的示例。
- 文件/报告测试器-555849.html-策略测试器报告。
- 文件/报告优化器-555849.xml-优化报告。
- files/report history-555849.html-交易历史报告。
- files/report.htm-使用HTML报告创建脚本创建的报告文件。
- files/style.css-report.htm的样式表
这篇文章是由俄罗斯原始
由Meta卫星软件公司在HTTPS://www. MQL5.COM/RU/TUNESL/5636中翻译而成。
MyFxtop迈投(www.myfxtop.com)-靠谱的外汇跟单社区,免费跟随高手做交易!
免责声明:本文系转载自网络,如有侵犯,请联系我们立即删除,另:本文仅代表作者个人观点,与迈投财经(www.myfxtop.cn)无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。