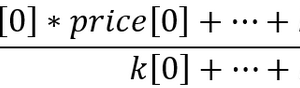在本文中,我们将继续探讨Kohonen网络作为交易员的工具。在第一部分中,我们修改和改进了开放类神经网络,并添加了必要的算法。现在,是时候在实际应用中使用它们了。本文将利用科隆图来解决优化EA参数的选择和时间序列的预测等问题。
寻找最优EA参数
共同原则
机器人优化已经在包括元交易员在内的许多交易平台中得到了解决。嵌入式测试人员提供工具、高级算法、分布式计算和细粒度统计评估。然而,从用户的角度来看,在优化过程中,总是有一个更为关键的最终阶段,即在分析程序生成的大量信息的基础上选择最终工作参数的阶段。在之前处理Kohonen图表并在本网站上发布的文章中,提供了可视化分析和优化结果的示例。但是,这意味着用户必须自己执行专家分析。理想情况下,我们希望从神经网络得到更具体的建议。简而言之,算法事务是通过程序进行的,不涉及用户。
经过优化后,我们通常会收到一份包含许多选项的长测试报告。根据要排序的列,我们从其深度提取绝对不同的设置,这意味着对相关标准(如利润、夏普比率等)的最佳性。即使我们建立了最可信的标准,系统通常也会提供几个具有相同结果的设置。如何选择?
一些交易者使用他们自己的综合标准来将几个标准指标纳入他们的计算中,使用这种方法,在报告中获得相同序列的可能性实际上就更少了。然而,事实上,他们将问题转化为上述标准的元优化域(如何正确地选择其公式?)这是一个独立的主题。因此,我们将返回到分析标准优化结果。
我认为,选择最佳的EA参数集必须基于搜索目标函数值范围内最长的持久“平台”,而不是基于搜索此类函数的最大值。在交易环境中,“高原”水平可与平均盈利能力进行比较,其长度可与可靠性进行比较,即系统的鲁棒性和稳定性。
在我们在第一部分中仔细考虑了一些数据分析技术之后,我们建议可以使用集群来搜索这样一个“平台”。
不幸的是,没有统一或通用的方法来获得具有所需特征的集群。特别是,如果集群的数量“太大”,它们将变小,并显示出重新学习的所有症状——它们很难总结信息。如果存在“太少”的集群,那么它们接受的培训就相当少,因此它们接收的样本基本上是不同的。“tai”这个词没有明确的定义,因为每个任务、数据数量和数据结构都有一个特定的阈值。因此,通常推荐几项实验。
集群的数量在逻辑上与图形的大小和应用程序的任务相关。在我们的示例中,前一个因子只在一个方向上起作用,因为我们决定通过公式(7)设置大小。因此,知道了这个大小,我们就得到了集群数量的上限——它们中没有一个可以超过一侧的大小。另一方面,根据应用程序的任务,可能只有一对集群适合我们的“好”和“坏”设置。这是实验的范围。所有这些都只适用于基于明确指示簇数的算法,如k-means。我们的替代算法没有这样的设置,但是因为集群是按质量排列的,所以我们可以从我们的考虑中排除所有数量高于给定集群的集群。
然后我们将尝试使用Kohonen网络进行集群。然而,在我们开始练习之前,我们必须讨论一个更好的观点。
许多机器人在大参数空间中进行了优化。因此,采用遗传算法进行优化,节省了时间和资源。然而,它有一个特殊的特点,即“落入”利润领域。原则上,这就是目的。然而,就Kohonen图而言,它不是很好。问题是,Kohonen映射对输入空间中的数据分布很敏感,实际上反映在生成的拓扑中。因为早期的遗传算法排除了错误的参数版本,所以它们发生的可能性比良好的继承版本小得多。因此,Kohonen网络可以忽略危险谷附近的目标函数找到的好版本。由于市场特征总是不稳定的,因此必须避免此类参数,在这些参数中,向左或向右的步骤会导致损失。
以下是解决问题的方法:
- 放弃遗传优化,喜欢完全优化。因为它是不可能完全实现的,我们可以采用分层的方法。首先,在一个大的步骤中进行遗传优化,然后对感兴趣区域进行定位,然后在其中进行整体优化(然后将Kohonen网络用于分析)。这也是一个想法。要优化的参数列表的过度扩展为系统提供了一定的自由度。这是因为它变得不稳定;其次,优化转化为拟合;因此,对于大多数参数,建议根据物理平均值选择永久值。例如,在基础分析中(如根据策略类型选择时间间隔:一天策略为日内策略,一周策略为中期策略等),可以减少优化空间,放弃继承。
- 例如,可以进行三次优化:按利润因素(pf),照常进行;按逆向质量(1/pf);按公式(min(pf,1/pf)/max(pf,1/pf),收集1附近的统计数据;将所有优化结果整合成一个统一的整体进行分析。
- 这是一个值得研究的半度量:用一个不包含优化指标(事实上,所有经济指标都不是EA参数)的度量来构造Kohonen图;换句话说,在网络教学中,神经元权重和输入之间的相似性的度量必须由所选的组件来计算。相对于ea参数,逆向测量也很有趣,因为邻近测量仅由经济指标计算,我们可以看到参数平面中的拓扑分散,这提供了系统不稳定的证据;在这两种情况下,神经元的重量以完整的方式进行拟合-基于所有成分。
N3的最后一个版本意味着网络拓扑将只反映EA参数的分布(或经济指标,取决于方向)。事实上,当我们在优化表的整行上训练网络时,诸如利润数、提取数和交易数等列构成了神经元的总分布,这不小于EA参数的分布。这将有助于我们对视觉分析有一个全面的了解,并得出结论,哪些参数对哪些指标影响最大。但这不利于我们对参数的分析,因为它们的实际分布会随着经济指标的变化而变化。
原则上,输入向量分为两个逻辑分离的部分:EA输入及其索引(输出)。Kohonen网络是在全矢量的基础上训练的。我们试图确定“输入”和“输出”(双向无条件关系)的依赖性。当网络只学习其一部分功能时,我们可以试着看到有向关系:如何根据“输入”聚合“输出”,反之亦然,如何根据“输出”聚合“输入”。我们将考虑这两种选择。
SOM探索者的进一步发展
为了实现这种训练模式,需要进一步开发CSOM和CSOMNODE类。
距离是在csomnode类中计算的。对于类中的所有对象,从计算中排除特定组件是统一的。因此,我们将对相关变量进行统计:
static int dimensionMax; static ulong dimensionBitMask;
Dimension Max可以设置要计算的最大神经元权重,例如,如果空间维度为5,DimensionMax等于4,则表示该向量的最后一个组件不包含在计算中。
维度位掩码可以使用位掩码排除随机位置的组件:如果位i等于1,则处理位i中的组件;如果位i等于0,则不处理。
让我们添加静态方法来放置变量:
static void CSOMNode::SetFeatureMask(const int dim = 0, const ulong bitmask = 0) { dimensionMax = dim; dimensionBitMask = bitmask; }
现在,我们将使用新变量更改距离计算:
double CSOMNode::CalculateDistance(const double &vector[]) const { double distSqr = 0; if(dimensionMax <= 0 || dimensionMax > m_dimension) dimensionMax = m_dimension; for(int i = 0; i < dimensionMax; i++) { if(dimensionBitMask == 0 || ((dimensionBitMask & (1 << i)) != 0)) { distSqr += (vector[i] - m_weights[i]) * (vector[i] - m_weights[i]); } } return distSqr; }
现在,我们只需要确保CSOM类以适当的方式对神经元施加限制。让我们向CSOM添加一个类似的公共方法:
void CSOM::SetFeatureMask(const int dim, const ulong bitmask) { m_featureMask = 0; m_featureMaskSize = 0; if(bitmask != 0) { m_featureMask = bitmask; Print("启用了特性掩码:"); for(int i = 0; i < m_dimension; i++) { if((bitmask & (1 << i)) != 0) { m_featureMaskSize++; Print(m_titles[i]); } } } CSOMNode::SetFeatureMask(dim == 0 ? m_dimension : dim, bitmask); }
在测试ea中,我们将创建字符串参数featuremask,用户可以在其中设置一个函数mask并对其进行分析,得到“1”和“0”字符:
ulong mask = 0; if(FeatureMask != "") { int n = MathMin(StringLen(FeatureMask), 64); for(int i = 0; i < n; i++) { mask |= (StringGetCharacter(FeatureMask, i) == '1' ? 1 : 0) << i; } } KohonenMap.SetFeatureMask(0, mask);
所有这些都是在训练方法开始之前完成的,因此距离计算在学习期间以及在U矩阵和簇的计算期间都会受到影响。然而,在某些情况下,通过其他规则实现集群是很有意思的,例如在没有任何掩码的情况下对网络进行教学,并且只应用掩码来查找集群。为此,我们还将在默认情况下引入控制参数applyFeatureMaskAfterTraining等于’false’。但是,如果设置为“真”,我们将在train方法之后调用setFeatureMask。
当我们再次改进我们的工具时,我们将触及另一个点,也就是说,我们将使用交易机器人的工作设置作为输入向量。
将EA参数的值上传到网络上,直接从设定的文件中进行分析,会更加方便。为此,让我们写下以下函数
bool LoadSettings(const string filename, double &v[]) { int h = FileOpen(filename, FILE_READ | FILE_TXT); if(h == INVALID_HANDLE) { Print("FileOpen 错误 ", filename, " : ",GetLastError()); return false; } int n = KohonenMap.GetFeatureCount(); ArrayResize(v, n); ArrayInitialize(v, EMPTY_VALUE); int count = 0; while(!FileIsEnding(h)) { string line = FileReadString(h); if(StringFind(line, ";") == 0) continue; string name2value[]; if(StringSplit(line, '=', name2value) != 2) continue; int index = KohonenMap.FindFeature(name2value[0]); if(index != -1) { string values[]; if(StringSplit(name2value[1], '|', values) > 0) { v[index] = StringToDouble(values[0]); count++; } } } Print("Settings loaded: ", filename, "; features found: ", count); ulong mask = 0; for(int i = 0; i < n; i++) { if(v[i] != EMPTY_VALUE) { mask |= (1 << i); } else { v[i] = 0; } } if(mask != 0) { KohonenMap.SetFeatureMask(0, mask); } FileClose(h); return count > 0; }
通过对设置文件的字符串进行分析,找出其中与训练后的网络特性相对应的参数名。一致的设置存储在向量中,不一致的设置被跳过。函数掩码只填充可用组件的单元,函数返回已读取设置的逻辑特性。
现在,当我们有需要的功能时,我们可以从设置文件中下载参数。我们将把下面的代码插入到IF操作符分支中,检查是否有数据文件名!=:
// 以特定模式方式处理 .set 文件 if(StringFind(DataFileName, ".set") == StringLen(DataFileName) - 4) { double v[]; if(LoadSettings(DataFileName, v)) { KohonenMap.AddPattern(v, "SETTINGS"); ArrayPrint(v); double y[]; CSOMNode *node = KohonenMap.GetBestMatchingFeatures(v, y); Print("Matched Node Output (", node.GetX(), ",", node.GetY(), "); Hits:", node.GetHitsCount(), "; Error:", node.GetMSE(), "; Cluster N", node.GetCluster(), ":"); ArrayPrint(y); KohonenMap.CalculateOutput(v, true); hasOneTestPattern = true; } }
设置将用设置标记。
工作EA
现在我们正在接近选择最佳参数的问题。
为了检验聚类优化结果的理论,首先必须建立一个有效的EA。我使用mql5向导和一些标准模块生成了它,并将其命名为wizardtest(它的源代码附在本文末尾)。以下是输入参数列表:
input string Expert_Title ="WizardTest"; // 文档名称 ulong Expert_MagicNumber =17897; // bool Expert_EveryTick =false; // //--- 主信号的输入参数 input int Signal_ThresholdOpen =10; // open [0...100] 的信号阈值 input int Signal_ThresholdClose =10; // close [0...100] 的信号阈值 input double Signal_PriceLevel =0.0; // 执行交易的价格水平 input double Signal_StopLevel =50.0; // 止损水平 (点数) input double Signal_TakeLevel =50.0; // 获利水平 (点数) input int Signal_Expiration =4; // 挂单的过期时间 (柱数) input int Signal_RSI_PeriodRSI =8; // 相对强弱指数 RSI (8,...)的计算周期数 input ENUM_APPLIED_PRICE Signal_RSI_Applied =PRICE_CLOSE; // 相对强弱指数 RSI(8,...) 价格序列 input double Signal_RSI_Weight =1.0; // 相对强弱指数 RSI(8,...) 权重 [0...1.0] input int Signal_Envelopes_PeriodMA =45; // Envelopes(45,0,MODE_SMA,...) 平均周期数 input int Signal_Envelopes_Shift =0; // Envelopes(45,0,MODE_SMA,...) 时间偏移 input ENUM_MA_METHOD Signal_Envelopes_Method =MODE_SMA; // Envelopes(45,0,MODE_SMA,...) 平均的方法 input ENUM_APPLIED_PRICE Signal_Envelopes_Applied =PRICE_CLOSE; // Envelopes(45,0,MODE_SMA,...) 价格序列 input double Signal_Envelopes_Deviation =0.15; // Envelopes(45,0,MODE_SMA,...) 偏移 input double Signal_Envelopes_Weight =1.0; // Envelopes(45,0,MODE_SMA,...) 权重 [0...1.0] input double Signal_AO_Weight =1.0; // AO指标权重 [0...1.0] //--- 用于跟踪止损的输入参数 input double Trailing_ParabolicSAR_Step =0.02; // 速度增加值 input double Trailing_ParabolicSAR_Maximum=0.2; // 最大比率 //--- 用于资金管理的输入参数 input double Money_FixRisk_Percent=5.0; // 风险百分比
对于我们的研究目标,我们将只优化一些参数,而不是全部参数。
Signal_ThresholdOpen Signal_ThresholdClose Signal_RSI_PeriodRSI Signal_Envelopes_PeriodMA Signal_Envelopes_Deviation Trailing_ParabolicSAR_Step Trailing_ParabolicSAR_Maximum
从2018年1月到6月(20180101-20180701),在欧元兑美元的d1,m1-ohlc中,我使用遗传算法根据利润对ea进行优化。本文末尾附加了包含要优化的参数的set文件(wizardtest-1.set)。优化结果保存在向导2018 Plus中。csv文件(也附在本文件末尾),不包括异常值,尤其是那些具有高且不相关的尖利系数和交易量小于5的异常值。此外,由于遗传算法优化的转变,我决定完全排除损失,只保留利润至少为10000的项目作为利润渠道。
我还删除了一对索引列,因为它们实际上依赖于其他列,例如余额或预期回报,以及其他候选列,例如pf(利润系数)、rf(反弹系数)和sharp-factor-高度相关。另外,rf与下降呈负相关,但我保留它们来证明它对图的依赖性。
选择能承受最大信息量的最小独立分量集输入结构是神经网络有效使用的关键条件。
打开包含优化结果的csv文件后,我们将看到上面提到的问题:大量字符串包含相同的利润指数和不同的参数。让我们试着做出一个合理的选择。
为了有一个参考点来评估我们将来要选择的选项,让我们从优化结果的第一个字符串中查看参数集的正向测试(请参见wizardtest-1.set)。试验日期为2018年7月1日至2018年12月1日。

首先列出所选设置中的测试报告
记住这些。实际上,它们不是很好的数字。我们需要把他们带到网络。
神经网络分析
CSV文件中的条目数目约为2000,因此由公式(7)计算的Kohonen网络大小为15。
我们启动了CSOM Explorer,输入了数据文件名(向导2018 Plus)。csv)在datafilename中,在cellsx和cellsy中输入15,并将epochnumber保持为100。要同时查看所有平面,我们选择小图像:每个图像w和h为210,而最大图片为6。通过实施企业体系运作,我们将取得以下实质性成果:

基于EA优化结果的Kohonen网络培训
第一行由经济指标图组成,第二行和第三行是EA的工作参数,最后五行是第一部分构建的特殊地图。
让我们仔细看看这些照片:

利润、pf、rf、前三个工作ea参数

夏普参数、取款、交易数量和EA中的最后三个参数

EA的最后一个参数,以及计数器、U矩阵、量化误差、集群和网络输出
让我们手动对获得的图形进行专家分析。
从利润上看,右上角和左上角是大致相等的区域(红色),右上角更大,突出度更高。然而,平面平行分析,加上pf、rf和尖锐因素,使我们相信右上角是最佳选择。这一点也得到了较少提款的证实。
让我们看看与EA参数相关联的组件,并注意右上角。在图形的前五个参数中,点的颜色是稳定的,允许我们自信地命名最佳值(将鼠标光标指向每个图形右上角的神经元,以在提示中看到相关值):
Signal_ThresholdOpen = 40 Signal_ThresholdClose = 85 Signal_RSI_PeriodRSI = 73 Signal_Envelopes_PeriodMA = 20 Signal_Envelopes_Deviation = 0.5
带有剩余两个参数的图形会主动更改右上角的颜色,因此不清楚要选择哪个值。从触发计数器的平面上看,右上角的神经元更为可取,合理地保证了它在U矩阵和误差图上是一个“安静的气氛”。由于这里一切正常,我们选择以下值:
Trailing_ParabolicSAR_Step = 0.15 Trailing_ParabolicSAR_Maximum = 1.59
让我们在2018年12月1日之前的同一时间段内使用这些参数运行EA(请参阅wizard test plus all features manual.set),我们将得到以下结果。

基于Kohonen图外观分析的选定设置测试报告
结果明显优于从第一个字符串中随机选择的结果。然而,它仍然会让专业人员失望,所以它值得在这里评论。
这是对EA的测试,不是圣杯。它的任务是生成源数据来演示基于神经网络的算法是如何工作的。文章发表后,将有可能在大量实际交易系统上测试这些工具,并对其进行调整以获得更好的结果。
让我们将当前结果与同一日期范围内csv文件中所有可用设置的主要值进行比较。

所有正向测试的结果

前验利润分配统计表
平均值为1007,标准差为1444,中位数为1085,最小值为3813.78,最大值为4202.82。因此,通过专家评价,我们获得了比平均加上标准差更高的利润。
我们的任务是学习如何自动地做出相同或定性的相似选择。为了这个目的,我们将使用聚类。由于集群按照其使用的优先顺序进行编号,我们将考虑集群0(不过,基本上,集群1-5可用于与设置组合进行交易)。
图中簇的颜色总是与它们的索引编号相关联,如下所示:
{clrRed, clrGreen, clrBlue, clrYellow, clrMagenta, clrCyan, clrGray, clrOrange, clrSpringGreen, clrDarkGoldenrod}
这可能有助于识别难以识别的较小图像上的数字。
SOM资源管理器在日志中显示集群中心的坐标,例如,当前图形的坐标:
Clusters [20]: [ 0] "Profit" "Profit Factor" "Recovery Factor" "Sharpe Ratio" [ 4] "Equity DD %" "Trades" "Signal_ThresholdOpen" "Signal_ThresholdClose" [ 8] "Signal_RSI_PeriodRSI" "Signal_Envelopes_PeriodMA" "Signal_Envelopes_Deviation" "Trailing_ParabolicSAR_Step" [12] "Trailing_ParabolicSAR_Maximum" N0 [3,2] [0] 18780.87080 1.97233 3.60269 0.38653 16.76746 63.02193 20.00378 [7] 65.71576 24.30473 19.97783 0.50024 0.13956 1.46210 N1 [1,4] [0] 18781.57537 1.97208 3.59908 0.38703 16.74359 62.91901 20.03835 [7] 89.61035 24.59381 19.99999 0.50006 0.12201 0.73983 ...
在开始的时候,有一些关于特性的描述。然后,对于每一个星团,它有它的数目,x和y坐标,以及特征值。
这里,对于集群0,我们有以下EA参数:
Signal_ThresholdOpen=20 Signal_ThresholdClose=66 Signal_RSI_PeriodRSI=24 Signal_Envelopes_PeriodMA=20 Signal_Envelopes_Deviation=0.5 Trailing_ParabolicSAR_Step=0.14 Trailing_ParabolicSAR_Maximum=1.46
我们将使用这些参数(wizardtest plus allfeatures auto nomask.set)运行正向测试并获取报告:

检测仪报告从Kohonen组自动选择的设置,无功能性屏蔽
结果并不比第一次随机试验好多少,明显比专家试验差。这都是关于集群的质量。目前,所有功能都是同时实现的,包括经济指标和EA参数。但是,我们应该只从交易数据中寻找“高原”。让我们将它们应用于只考虑它们的特征遮罩的集群,即前六个特征遮罩。为此,设置:
FeatureMask=1111110000000 FeatureMaskAfterTraining=true
然后重新开始学习。在som explorer中,集群化是在学习的最后阶段进行的,而得出的集群会保存在网络文件中。This is necessary for the network loaded later to be used immediately to“identify”new samples.这些样本包含的索引可能比所有索引都少(即,向量可能不完整),例如在分析收集文件时——它只包含EA参数,但不包含经济索引(它们毫无意义)。因此,对于这些示例,在函数loadsettings中构建它们自己的特征遮罩,该函数对应于向量的现有组件,然后将遮罩应用于网络。因此,为了不与要“识别”的向量的掩码冲突,集群掩码必须隐式存在于网络中。
但让我们回到学习如何使用新的面具。它将改变U矩阵和簇的平面。集群的模式将发生显著变化(应用遮罩之前的左图像和应用遮罩之后的右图像)。
0
在Kohonen的图表中,没有基于经济指数应用遮罩的集群(左)和(右)。
现在,0个集群的数量是不同的。
N0 [14,1] [0] 17806.57263 2.79534 6.78011 0.48506 10.70147 49.90295 40.00000 [7] 85.62392 73.51490 20.00000 0.49750 0.13273 1.29078
如果你还记得,我们在专家评估中选择了右上角的神经元,它有坐标[14,0]。现在,这个系统为我们提供了相邻的神经元[14,1]。他们的体重并没有很大的不同。让我们把提议的设置转移到工作EA的参数。
Signal_ThresholdOpen=40 Signal_ThresholdClose=86 Signal_RSI_PeriodRSI=74 Signal_Envelopes_PeriodMA=20 Signal_Envelopes_Deviation=0.5 Trailing_ParabolicSAR_Step=0.13 Trailing_ParabolicSAR_Maximum=1.29
我们将取得以下成果:
1
使用Economic Indicators(经济指标)页面自动从Kohonen图表群集测试仪报告中选择设置。
无论参数有什么不同,它们都与专家的结果相同。
为了便于将集群结果移动到EA设置中,我们将编写一个助手函数,该函数使用所选集群功能的名称和值(默认值为零)生成一个集合文件。该函数名为savesettings,如果新参数saveclusterassettings包含要导出的集群的索引,则该函数将开始运行。默认情况下,此参数包含-1,这意味着不需要生成设置文件。显然,这个函数并不“知道”这些特性的应用意义,并将它们全部保存在聚合文件中,因此也会有诸如利润、利润因素等贸易指数。用户只能从生成的文件中复制与EA实际参数对应的函数。参数值保存为实数,因此必须对整数参数进行更正。
现在,我们可以将找到的设置保存为可移植的形式,让我们为集群0创建设置(向导2018加上集群0.set),并将它们加载回SOM资源管理器(应该提醒我们的实用程序已经能够读取设置文件)。在参数netfilename中,您需要指定在上一个学习阶段(wizard 2018 plus)创建的网络的名称。SOM,因为我们使用向导2018 Plus。csv数据-它存储在每个学习周期的文件中,文件名是输入名,但扩展名是。SOM)。在参数datafilename中,我们将指定生成的收集文件的名称。标签设置将与集群C0的中心重叠。
我们将用网络重命名SOM文件,因为它在随后的实验中不会被重写。
第一个实验如下。我们将使用EA参数(不包括事务数据)来教网络“反向”屏蔽。为此,我们将指定文件wizard2018plus。csv再次在参数datafilename中,清除参数netfilename并设置
FeatureMask=0000001111111
请注意,FeatureMask Aftertraining仍然设置为“true”,这意味着该遮罩只影响群集。
学习后,我们将加载教学网络和测试设置。为此,我们将移动创建的网络文件向导2018的名称。SOM到参数NETFrimeNeNe和复制向导2018加上服务器0。再次向DataFileName致敬。总的图集将保持不变,而U矩阵和簇将变得不同。
聚类结果如下图左侧所示:
2
Kohonen网络上的集群在EA参数上使用一个掩码构建:仅在集群阶段(左)和网络学习和集群阶段(右)。
设置的选择是由它们达到零簇并且更大这一事实来确认的。
作为第二个实验,我们将使用相同的掩模(通过EA参数)再次教授网络。但是,我们也将在学习阶段进行扩展:
FeatureMaskAfterTraining=false
完整的图集如下图所示,在上图右侧,集群中的变化比例较大。在这里,神经元只通过参数的相似性聚集在一起。这些图表应该理解为:在选定的参数下,预期会出现什么经济指标?尽管集群2的测试设置有所下降(比集群2差,但不多),但它的大小是最大的,这是一个积极的特性。
3
由ea参数用密码构造的kohonen图
有兴趣的读者会注意到,具有经济指标的图不再具有这种拓扑性质。但是,现在不需要这样做,因为检查的本质是根据参数识别集群的结构,并确保所选设置位于集群系统中。
“逆向”研究将是一个完整的学习和集群,涵盖经济指标:
FeatureMask=1111110000000 FeatureMaskAfterTraining=false
结果是:
4
用经济指数掩模构造的Kohonen图
现在,对比色集中在经济指数的前六个平面上,而参数图则是无定形的。特别是,我们可以看到,参数trailing_抛物线sar_step和trailing_抛物线sar_maximum的值实际上是不变的(图是单调的),这意味着它们可以从优化中排除,分别基于0.11和1.14的平均值。在参数图中,信号阈值打开与之形成了鲜明的对比。由此可见,选择0.4的信号阈值打开是成功交易的必要条件。U矩阵图清楚地分为两个“池”,两个“池”代表成功,两个“池”代表失败。触摸图是非常稀缺和不均匀的(空间的最大部分是间隙,而活跃的神经元有很大的反价值),因为在所研究的EA中,利润是按几个不同的水平分组的。
这些地图应该理解为:在选定的经济指标中,预期会出现哪些参数?
最后,对于前面的实验,我们将稍微开发SOM资源管理器,以便它能够合理地命名集群。让我们编写函数setcluster labels,它将分析每个集群中代码向量的特定组件的值,并将它们与这些组件的值范围进行比较。一旦神经元中的权重值接近最高或最低值,这就是为什么它用相关组件的名称标记的原因。例如,如果零关系(对应于利润)的权重大于其他集群,则说明该集群具有高利润的特点。需要注意的是,极值(最大值或最小值)的符号是由表示的含义决定的:利润越高,值越高越好;提款时,值越高。在这方面,我们引入了一个特殊的输入,即特征方向,其中我们将用“+”符号标记正指令,用“-”符号标记负指令,用“,”符号跳过不重要或无意义的指令。请注意,在我们的情况下,只标记经济指标是合理的,因为EA的工作参数值可以是任何值,并且根据其与定义边界的近似值,它不会被解释为好或坏。因此,我们只为前六个函数设置特征方向的值:
FeatureDirection=++++-+
这是标签如何找到网络上学习的全矢量和分类的经济指标(左),以及网络上的口罩的EA参数的学习和分类。
5
集群标签给出了以下场景:集群阶段(左侧)使用经济指标屏蔽,学习和集群阶段(右侧)使用参数屏蔽。
我们可以看到,在这两种情况下,所选的设置都属于利润因素集群,因此我们可以期望该指标的效率最高。但是,应该考虑到这里的所有标签都是阳性的,因为源数据是从遗传优化中获得的,遗传优化是选择可接受选项的过滤器。如果对完全优化的数据进行分析,那么我们可以根据集群的性质将其识别为负的。
因此,在一般情况下,我们考虑使用Kohonen图上的聚类来搜索EA的最佳参数。因为这种方法是灵活的,所以很复杂。它意味着使用各种聚类和网络教学方法,以及预处理输入。寻找最佳选择也很大程度上取决于工作机器人的特殊性。SOM Explorer提供的工具允许我们开始研究这部分数据处理,并对其进行扩展和改进。
优化结果的颜色分类
由于聚类方法和质量严重影响对最佳EA设置的正确搜索,因此让我们尝试以更简单的方式解决相同的问题,而不评估神经元的接近度。
让我们在RGB颜色模型中显示Kohonen图上的特征权重,然后选择最轻的点。由于RGB颜色模型由三个平面组成,因此我们可以用这种方式精确地显示三个特征。如果它们或多或少存在,我们将使用灰色渐变来显示亮度而不是RGB颜色,但仍然可以找到最轻的点。
重要的是要注意,在选择函数时,最好选择最独立的函数(前面提到)。
在实现新方法时,我们还将演示以我们自己的方式扩展类CSOM的可能性。让我们创建一个类csomdisplay rgb,在这个类中,我们只重写父csomdisplay的一些虚拟方法,并使用这个方法来实现将显示的rgb映射,而不是最后一个dim_输出平面。
class CSOMDisplayRGB: public CSOMDisplay { protected: int indexRGB[]; bool enabled; bool showrgb; void CalculateRGB(const int ind, const int count, double &sum, int &col) const; public: void EnableRGB(const int &vector[]); void DisableRGB() { enabled = false; }; virtual void RenderOutput() override; virtual string GetNodeAsString(const int node_index, const int plane) const override; virtual void Reset() override; };
完整的代码在附件中。
要使用此版本,让我们创建修改后的SOM资源管理器RGB版本并进行以下更改。
添加输入参数以启用RGB模式:
input bool ShowRGBOutput = false;
图形对象将成为派生类:
CSOMDisplayRGB KohonenMap;
我们将在单独的代码分支中直接显示RGB平面:
if(ShowRGBOutput && StringLen(FeatureDirection) > 0) { int rgbmask[]; ArrayResize(rgbmask, StringLen(FeatureDirection)); for(int i = 0; i < StringLen(FeatureDirection); i++) { rgbmask[i] = -(StringGetCharacter(FeatureDirection, i) - ','); } KohonenMap.EnableRGB(rgbmask); KohonenMap.RenderOutput(); KohonenMap.DisableRGB(); }
它使用了我们已经熟悉的特征方向参数,我们可以用它来选择要包含在RGB空间中的特定功能(整个特征集的功能)。例如,对于向导2018 Plus示例,您只需编写:
FeatureDirection=++,,-
对于前两个功能,即利润和利润,直接转到地图(它们对应于“+”符号),而第五个功能,即提取,是一个反转值(它对应于“-”符号)。跳过’,’的功能。不考虑所有后续行动。wizardtest-rgb.set文件及其设置附加在此处(网络文件wizard2018plus.som应在上一阶段提供)。
这是这些设置在RGB空间(左侧)中的显示方式。
6
功能RGB空间(利润、PF和退出)和(PF、退出和交易)
颜色与优先顺序中的特征相关:利润是红色,PF是绿色,退出是蓝色。最亮的神经元被标记为“rgb”。
记录显示了“最轻”神经元的坐标及其特征值,可作为最佳设置选项。
由于利润与PF的相关性很强,我们将用另一个面具来代替它:
FeatureDirection=,+,,-+
在这种情况下,会跳过利润,但交易数量会增加(一些经纪人提供批量奖金)。结果如上图所示(右侧)。这里,颜色匹配是不同的:pf是红色,支取是绿色,事务数是蓝色。
如果只选择函数pf和undo,将得到灰色映射(在左侧):
7
RGB空间的功能(PF和退出)和(利润)
为了检查,我们只能选择一个函数,例如利润,并确保黑白模式对应于第一个平面(参见上面图的右侧)。
正向测试分析
据了解,元交易者测试仪允许对所选设置进行正向测试,以补充EA优化。如果不尝试使用Kohonen图来分析这些信息,并以这种方式为设置选择特定的选项,那将是愚蠢的。从概念上讲,过去和未来高利润地区的集群或颜色区域必须包括提供最稳定收入的设置。
为此,让我们将wizardtest的优化结果与转发测试相结合(我要提醒您,利润在20180101-20180701期间进行了优化,转发测试在20180701-20181201期间进行了相应的优化),删除除过去和未来利润之外的所有指令,并获得一个新的输入参数f用于网络的ILE-WIZARD2018,带FO。rward.csv(附件)。还附加了一个设置为wizardtest-with-forward.set的文件。
通过对所有函数(包括EA参数)进行网络教学,可以得到以下结果:
8
Kohonen图,它利用所有特征进行正向测试分析,即利润因子和EA参数。
我们可以看到,未来利润的区域明显小于过去利润,零集群(RED)包含这个位置。此外,我还包括两个遮罩颜色分析指示器(featuredirection=++),以及最后一个进入集群的图形上最亮的点。然而,无论是集群中心还是淡色点都不包含任何超级有利可图的设置——尽管测试结果是阳性的,但它们的糟糕程度是之前结果的两倍。
让我们尝试在前两个特性上使用遮罩构建一个Kohonen图,因为只有这些是指令。为此,让我们应用featuremask=1100000的其他设置(请参阅wizard test-with-forward-mask11.set)并重新连接网络。结果如下。
9
基于利润因素的正向检验分析Kohonen图
在这里,我们可以看到前两个平面已经获得了最佳的表达空间结构,并且跨越了左下角的高值(利润)区域,这在最后一张地图中也被突出显示。从神经元中检索设置后,我们将得到以下结果:
0
按“利润稳定”原则选择设置的测试报告
这也比以前的利润更糟。
因此,这个实践性的实验不允许我们找到最佳的设置。同时,将正向测试结果纳入神经网络分析似乎是正确的,这应该是一种推荐的方法。我们建议在评论中讨论在任何情况下,成功都缺少哪些细微差别,以及成功是否有保障。或许,结果只是证明我们的测试EA不适合稳定的交易。
时间序列预测
概述
Ohonen网络最常用于对数据进行可视分析和聚合类,但也可用于预测。这个问题意味着输入数据向量代表tic标签,它的主要部分通常是大小(n-1),n是向量大小,应该用来预测结束,这通常是最新的tic标签。本质上,这个问题类似于恢复噪声或部分丢失的数据。然而,它有自己的特异性。
使用Kohonen网络有不同的预测方法,下面是其中的一些。
Kohonen网络(A)学习不完全向量大小(n-1)的数据,也就是说,没有最后一个组件。对于第一个网络的每个神经元i,为一组n大小的截断全矢量(对应于网络a的n个神经元i所示的不完整矢量)设置n个附加的Kohonen映射(bi>;)。随后,在运行时,根据预测向量进入网络A的神经元I后从网络BI获得的概率,模拟未来的勾号标记。
另一个选择。在Kohonen图中,A是关于全向量的。第二Kohonen图(B)是关于修改向量。在修改向量时需要增量而不是值。
yk=xk+1 xk,k=1。N 1
YK和XK分别是初始矢量和修正矢量的分量。显然,修正向量的大小比初始向量小一倍。然后将教学数据输入两个网络,计算第一个网络中神经元i和第二个网络中神经元j同时显示的全矢量数。因此,我们得到了Y矢量进入神经元J(在网络B中)的条件概率pij,前提是与其相关的向量x已经进入神经元I(在网络A中)。在操作阶段,网络A由一个不完整的向量x(没有最后一个分量)输入i n,找到(n-1)分量最近的神经元i*,并根据概率pi*生成电位增量。与其他方法一样,该方法与蒙特卡罗方法有关。蒙特卡罗方法根据教学选择得到的数据填充神经元的统计数据,生成待预测成分的随机值,找到最可能的结果。
这个列表可以持续更长的时间,因为它包括了SOM神经元上所谓的参数SOM和自回归模型,甚至包括嵌入空间中随机吸引子的聚集。
然而,它们或多或少是基于代表Kohonen网络的矢量量化现象。随着网络学习的进行,神经元的权重逐渐趋向于它们所代表的类(输入子集)的平均值。这些平均值中的每一个都通过使用与教学选择相同的统计规则来提供对新数据中缺失(或预测未来)值的最佳评估。班级越紧凑,划分越清楚,评价越准确。
我们将使用最简单的基于矢量量化的预测方法,它涉及一个单一的Kohonen网络实例。然而,即使是这一个也会带来一些困难。
我们将为网络输入提供时间序列的全矢量。但是,只计算第一个(n-1)分量的距离。重量完全适用于所有部件。然后,为了预测的目的,我们将不完全向量输入到网络中,找到最合适的神经元组分(n-1),并读取最后n个突触的权重。这将是预测。
在CSOM课程中,我们已经准备好了。下面是setFeatureMask方法,它在计算距离所涉及的特征空间大小上设置一个遮罩。然而,在实现算法之前,我们应该决定预测什么。
聚类指数统一
在交易者中,一系列的报价被认为是一个非常重要的时间过程。它包含许多随机、频繁的相位变化和大量的影响因素。原则上,它是一个开放的系统。
为了简化问题,我们将选择一个更大的时间段进行分析,即每天的时间段。在这段时间内,噪声对较小的时间周期影响不大。此外,我们还将选择一种预测工具,在这种工具中,能够无限地推动市场的强劲基本消息相对较少。在我看来,最好的是金属,即金银。它们不是任何特定国家的支付工具。它们既是原材料,又是保护性资产。一方面,它们的波动性较小,另一方面,它们与货币有着千丝万缕的联系。
理论上,他们未来的行动应该考虑到当前的报价,并对外汇报价作出反应。
因此,我们需要一种方法来获得金属和基础货币价格的同步变化,以便对其进行总结。在任何给定的时间,这必须是一个包含n个分量的向量,每个向量对应于一个货币或金属的相对成本。预测的目的是通过这样的向量来预测一个分量的下一个值。
为此,创建了原来的簇指示符统一(它的源代码附加在这里)。其操作的本质由以下算法描述。让我们考虑一下,尽可能简单地通过一对货币(欧元兑美元)和黄金(XAUDUS)来说明这一点。
每个TIC标签(当前价格在一天的开始/结束)是由一个明确的公式描述:
欧元/美元=欧元/美元
Xau/美元=Xauusd
欧元、美元和Xau变量是资产的独立“成本”,而欧元美元和Xauusd是常量(已知报价)。
为了找到变量,让我们在系统中添加另一个方程,将变量和限制为一个单位:
欧元*欧元+美元*美元+Xau*Xau=1
所以指标的名称是统一的。
通过简单的替换,我们得到:
欧元兑美元
我们正在寻找美元:
美元=sqrt(1/1+欧元兑美元*欧元兑美元+xauusd*xauusd)
以及所有其他变量。
或者更一般的表现:
X0=SqRT(1/1 +和(C(Xi,X0)** 2),i=1)。n
X= C(Xi,X0)*X0,i=1。n
其中,N是变量的数目,C(XI,X0)是第一对的引用,包括相关变量。注意变量的数量比仪器的资产数量高1。
由于计算中涉及的系数c是通常变化很大的引号;在指标中,它们乘以合同大小:因此,结果值或多或少具有可比性(或至少具有相同数量级),以便在指标窗口中查看它们(仅供参考),输入名为绝对值nEED设置为真。默认情况下,它当然是错误的,指示器总是计算变量的增量:
yi=xi0/xi1-1,
xi0和xi1分别是最后一列和倒数第二列的值。
我们不会在这里考虑指示器实现的技术细节——您可以独立地研究它的源代码。
因此,我们得出以下结果:
1
集群(多货币)指标统一,xauusd
构成当前图表工具的资产行(在本例中是Xau和美元)显示得很宽,而其他行的厚度正常。
指标输入参数中应注意以下几点:
- 仪器-一组逗号分隔的工作工具名称;所有工具的基础货币或报价货币必须相同;
- barlimit——用于计算的列数;一旦我们教授神经网络,它将成为教学选择的大小;
- savetofile csv文件的名称以及将加载到神经网络中的索引值将导出到该文件。文件结构简单:第一列为日期,后续所有列为相关索引缓冲区的值;
- shiftlastbuffer-切换模式标志以在此模式下生成csv文件;如果选项为false,则在文件中的每个字符串中显示相同的数据,列数等于仪器数加上一个(因为勾号器分为多个组件),再加上一个(第一个)列作为日期;列名c与货币和金属相关。;如果该选项为真,则添加一个名为forecast的附加列,其中保存最后一项资产的列的值向前移动一天;因此,在每个字符串中,我们可以在最后一个工具中看到当前和明天的所有数据。
例如,要准备一个包含预测金价变化数据的文件,您应该在参数instruments中指定:“eurrusd、gbps、usdhf、usdhpy、auddusd、usdcad、nzdusd、xauusd”(最后指定xauusd很重要),并且在shiftlastbuffer中必须指定“true”。我们将得到一个基本上具有以下结构的csv文件:
datetime; EUR; USD; GBP; CHF; JPY; AUD; CAD; NZD; XAU; FORECAST 2016.12.20 00:00:00; 0.001825;0.000447;-0.000373; 0.000676;-0.004644; 0.003858; 0.004793; 0.000118;-0.004105; 0.000105 2016.12.21 00:00:00; 0.000228;0.003705;-0.001081; 0.002079; 0.002790;-0.002885;-0.003052;-0.002577; 0.000105;-0.000854 2016.12.22 00:00:00; 0.002147;0.003368;-0.003467; 0.003427; 0.002403;-0.000677;-0.002715; 0.002757;-0.000854; 0.004919 2016.12.23 00:00:00; 0.000317;0.003624;-0.002207; 0.000600; 0.002929;-0.007931;-0.003225;-0.003350; 0.004919; 0.004579 2016.12.27 00:00:00;-0.000245;0.000472;-0.001075;-0.001237;-0.003225;-0.000592;-0.005290;-0.000883; 0.004579; 0.003232
请注意,最后两列包含相同的数字,并按一行移动。因此,在2016年12月20日的字符串中,我们可以在预测列中看到Xau当天和12月21日的增量。
SOM预测
是时候实现基于Kohonen网络的预测引擎了。首先,为了理解它是如何工作的,我们将建立在已知的SOM资源管理器之上,并使其适应预测问题。
修改围绕着输入旋转,因此让我们删除与设置遮罩相关的所有内容:FeatureMask、应用FeatureMask、Aftertraining和Feature Direction,因为预测遮罩已知-如果n tic标记的矢量大小可用,则只有第一个(n-1)标记应参与计算距离。但是我们要添加一个特殊的逻辑选项,预测模式,它允许我们在必要时禁用这个屏蔽,并使用Kohonen网络的经典分析功能。我们需要这样做来探索市场,或者更准确地说,在静态状态下统一指定的工具系统,也就是说,在同一天内看到相关性。
在预测模式等于“真”的情况下,我们放置了一个蒙版,如果它为“假”,就没有蒙版。
if(ForecastMode) { KohonenMap.SetFeatureMask(KohonenMap.GetFeatureCount() - 1, 0); }
一旦设置了网络,并且在输入数据文件名中指定了包含测试数据的csv文件,我们将在预测模式下检查预测质量,如下所示:
if(ForecastMode) { int m = KohonenMap.GetFeatureCount(); KohonenMap.SetFeatureMask(m - 1, 0); int n = KohonenMap.GetDataCount(); double vector[]; double forecast[]; double future; int correct = 0; double error = 0; double variance = 0; for(int i = 0; i < n; i++) { KohonenMap.GetPattern(i, vector); future = vector[m - 1]; // 为将来保留 vector[m - 1] = 0; // 使网络的未来未知(由于掩码,它无论如何都不使用) KohonenMap.GetBestMatchingFeatures(vector, forecast); if(future * forecast[m - 1] > 0) // 检查方向是否匹配 { correct++; } error += (future - forecast[m - 1]) * (future - forecast[m - 1]); variance += future * future; } Print("Correct forecasts: ", correct, " out of ", n, " => ", DoubleToString(correct * 100.0 / n, 2), "%, error => ", error / variance); }
在这里,每个测试向量被呈现给网络使用GETBEST匹配特征响应于“预测”向量。将最后的分量与测试向量的正确值进行比较。在“正确”变量的匹配方向的计算中,总预测“误差”是累积的,并且与数据本身的分散有关。
如果填充了validation set percent参数,则将该方法设置为方法,并且reframenumber大于零,则在操作中使用csom的新函数trainandreframe。它允许我们分阶段地增加网络规模,并跟踪验证集中学习错误的变化,以便当错误停止下降并开始增长时,过程立即停止。此时,由于网络计算能力的增强,权值适应于特定的向量,从而导致泛化的损失和处理未知数据的能力。
在选择了大小后,我们将验证集百分比和折射率重置为0,并像往常一样使用训练方法来教网络。
最后,我们将稍微改变集群setcluster标签中标签的功能。因为资产将是特征,并且每个都可以显示正极端和负极端,我们将在标签中包含移动标签。因此,在地图上可以找到两个相同的特征,正负。
void SetClusterLabels() { const int nclusters = KohonenMap.GetClusterCount(); double min, max, best; double bests[][3]; // [][0 - value; 1 - feature index; 2 - direction] ArrayResize(bests, nclusters); ArrayInitialize(bests, 0); int n = KohonenMap.GetFeatureCount(); for(int i = 0; i < n; i++) { int direction = 0; KohonenMap.GetFeatureBounds(i, min, max); if(max - min > 0) { best = 0; double center[]; for(int j = nclusters - 1; j >= 0; j--) { KohonenMap.GetCluster(j, center); double value = MathMin(MathMax((center[i] - min) / (max - min), 0), 1); if(value > 0.5) { direction = +1; } else { direction = -1; value = 1 - value; } if(value > bests[j][0]) { bests[j][0] = value; bests[j][1] = i; bests[j][2] = direction; } } } } // ... for(int j = 0; j < nclusters; j++) { if(bests[j][0] > 0) { KohonenMap.SetLabel(j, (bests[j][2] > 0 ? "+" : "-") + KohonenMap.GetFeatureTitle((int)bests[j][1])); } } }
所以让我们考虑准备好SOM预测,现在我们将尝试使用它来输入统一度量的值。
分析
首先,让我们尝试在静态或更精确的统计环境中分析整个市场(所选资产集),也就是说,在严格按天从指标单位派生的数据中-每个字符串对应于d1中的一条指令,而“未来”中没有任何额外的列。
为此,我们将在指示器中指定一组外汇工具(黄金和白银)以及savetofile中的文件名,并将shiftlastbuffer设置为“false”。以这种方式获得的文档unity500-noshift.csv附在本文末尾。
使用som forecast(请参见som-forecast-unity500-noshift.set)将这些数据教给网络后,我们将得到下图:
2
用统一指数在d1上对Kohonen地图上的外汇市场、黄金和白银进行可视化
上面的两行是资产图。通过比较,我们可以确定至少在过去500天内工作的永久链接。特别是,色斑的两个中心引起了人们的注意:蓝色表示英镑,黄色表示澳元。这意味着这些资产通常处于反向阶段,仅指剧烈波动,即当市场平均方差突破时,英镑对澳元的销售占主导地位。这一趋势很可能会继续下去,并提供了向这个方向下订单的选择。
在CHF所在的右上角观察到xag生长。在左下角,情况正好相反:CHF上升而XAG下降。这些资产总是在剧烈波动中出现分歧,因此我们可以通过两个方向的突破进行交易。正如预期的那样,欧元和瑞士法郎是相似的。
图中还可以找到其他特定功能。事实上,甚至在我们开始预测之前,我们就有机会在某种程度上预测未来。
让我们仔细看看集群。
3
根据d1的统一指数,Kohonen图上的外汇、金银集群
它们还提供了一些信息,例如,关于通常不会发生(或很少发生)的事情,也就是说,欧元不会随着日元或美元的下跌而增长。英镑通常与瑞士法郎同时增长,反之亦然。
就集群规模而言,欧元、英镑和瑞士法郎波动最多。也就是说,它们比其他货币更频繁地发生变化,美元在这方面意外地下跌到日元和加拿大元(我们需要提醒我们,我们将计算这个变化为%)。如果我们假设簇的数目也是重要的(我们已经排序它们),那么前三个是+CHF、-JPY和+GBP,这清楚地描述了最频繁的日常运动(不是趋势,而是频率),因为即使在“平滑”的时期,大量的“梯子”也可以通过一个大的“梯子”来补偿。
现在,我们来谈谈预测。
预报
让我们在指标中指定一组工具,包括外汇和黄金(“欧元兑美元、英镑兑美元、美元兑瑞士法郎、美元兑日元、澳元兑美元、美元兑加元、新西兰元兑美元、xauusd”)、barlimit中的列号(默认值为500)、savetofile中的文件名(例如unity500xau)。csv),并将shifttbuffer标志设置为“真”(创建预测附加列的模式)。由于它是一个多货币指标,可用数据的数量仅限于所有工具的最短历史记录。在MetaQuotes演示服务器上,有足够数量的柱,至少2000条,用于时间段d1。因此,在这里考虑另一个问题会很有帮助:在线教育是否合理到这样的深度,因为市场很可能会发生很大的变化。2-3年甚至1年的历史(D1上有250根柱子)可能更适合确定现行法律。
本文档末尾附有Unity500xau.csv文件的示例。
要将其加载到SOM Forecast中,我们将设置以下输入:数据文件名Unity 500Xau、Forecast Mode true、验证集Percent-10,重要的是,Reframenumber-10。这样,我们将运行10*10网络大小教学(默认值),并在验证选择上启用错误检查,并通过逐渐增加网络大小,同时减少错误继续教学。在trainandreframe方法中,大小将增加10个,每个维度有两个神经元。因此,我们将检测输入的最佳网络大小。包含设置(som forecast unit 500xau.set)的文件已附加。
在逐步教学和增加网络的同时,日志中显示以下内容(以缩写形式提供):
FileOpen OK: unity500xau.csv HEADER: (11) datetime;EUR;USD;GBP;CHF;JPY;AUD;CAD;NZD;XAU;FORECAST Training 10*10 hex net starts ... Exit by validation error at iteration 104; NMSE[old]=0.4987230270708455, NMSE[new]=0.5021707785446128, set=50 Training stopped by MSE at pass 104, NMSE=0.384537545433749 Training 12*12 hex net starts ... Exit by validation error at iteration 108; NMSE[old]=0.4094350709134669, NMSE[new]=0.4238670029035179, set=50 Training stopped by MSE at pass 108, NMSE=0.3293719049246978 ... Training 24*24 hex net starts ... Exit by validation error at iteration 119; NMSE[old]=0.3155973731785412, NMSE[new]=0.3177587737459486, set=50 Training stopped by MSE at pass 119, NMSE=0.1491464262340352 Training 26*26 hex net starts ... Exit by validation error at iteration 108; NMSE[old]=0.3142964426509741, NMSE[new]=0.3156342534501801, set=50 Training stopped by MSE at pass 108, NMSE=0.1669971604289485 Exit map size increments due to increased MSE ... Map file unity500xau.som saved
这样,进程在26*26网络上停止。在表面上,我们应选择最小误差为24*24的位置。但事实上,当我们使用神经网络时,我们总是利用机会。如果您还记得,randomseed负责初始化用于在网络中设置初始权重的随机数据生成器。每次我们改变随机种子,我们就会得到一个新的具有新特性的网络。此外,所有其他因素都是平等的,而且比其他情况更好或更糟。因此,为了选择网络的大小和其他设置,包括教学选择的大小,我们通常要做很多尝试,犯很多错误。然后,我们将遵循这一原则,减少教学数据的选择,并将网络的大小减少到15*15。此外,我有时会使用非规范化修改的矢量时间量化方法描述。修改包括禁用标志预测模式时对网络进行教学,以及仅在进行预测时启用模式。在某些情况下,这可能会产生积极的影响。与神经网络合作从来没有推荐即食,只是食谱。实验是不被禁止的。
在教学之前,源文件(在我们的示例中,Unity500xau)。csv)应分为两部分。问题在于,在教学过程中,我们需要验证一些数据的质量。在网络用于学习的相同数据上这样做没有任何意义(更准确地说,你只需要自己看到很高比例的正确答案-你可以检查它)。所以让我们复制50个向量,在单独的文件中测试它们,并使用静态向量来教授新的网络。您可以找到附件Unity500xau-training.csv和Unity500xau-validation.csv。
让我们在参数datafilename(扩展名)中指定单元500xau训练。csv是隐式的)。cellsx和cellsy的值应为24,验证集百分比为0,reframenumber为0,预测模型仍为“真”(请参阅som forecast unit 500xau training.set)。经过培训,我们将得到以下图片:
4
Enter Kohonen
这不是预测,而是一个视觉确认网络,它已经学会了一些东西。具体来说,我们将检查输入是否已经提供了验证文件。
要做到这一点,让我们输入以下设置。文件名unity500xau training现在将传输到参数netfilename(这是具有隐式扩展名的设置网络文件名)。SOM)。在参数datafilename中,我们指定unity500xau验证。网络将预测所有向量并在日志中显示统计信息:
Map file unity500xau-training.som loaded FileOpen OK: unity500xau-validation.csv HEADER: (11) datetime;EUR;USD;GBP;CHF;JPY;AUD;CAD;NZD;XAU;FORECAST Correct forecasts: 24 out of 50 => 48.00%, error => 1.02152123166208
唉,预测的准确度是随机猜测的水平。如此简单的输入选择能产生圣杯结果吗?也许不是。此外,我们只是猜测历史的深度,这个问题必须加以研究。我们还应该使用一组工具,例如添加白银,并且通常要澄清哪些资产更依赖于其他资产,以便轻松预测。接下来我们将考虑一个使用银的例子。
为了在输入中引入更多的上下文,我在Indicator Unity中添加了一个选项,以形成一个仅基于日期和最近几天的向量。为此,添加参数barlookback,默认等于1,对应于前一个模式。但是,如果我们在这里输入5,向量将在5天内包含所有资产的tic标记(基本上,一周是基本周期之一)。如果有九种资产(八种货币和黄金),则在csv文件的每个字符串中存储46个值。总之,计算速度要慢得多,分析图表也要困难得多:即使是小的图表也很难在屏幕上显示,而大的图表可能比图表上的历史记录要短。
请注意,在对象模式下查看如此多的图形时,例如obj_bitmap(max pictures=0),图形上可能没有足够的条:它们是隐藏的,但仍用于链接图像。
为了演示这个方法的性能,我决定在3天的回顾时间和15*15的网络中查看它。我们添加了unity1000xau3-training.csv和unity1000xau3-validation.csv文件,在第一个文件中训练网络,在第二个文件中验证网络,我们将得到58%的准确预测。
载入 unity1000xau3-training.som 文件 FileOpen OK: unity1000xau3-validation.csv HEADER: (29) datetime;EUR3;USD3;GBP3;CHF3;JPY3;AUD3;CAD3;NZD3;XAU3;EUR2;USD2;GBP2;CHF2;JPY2;AUD2;CAD2;NZD2;XAU2;EUR1;USD1;GBP1;CHF1;JPY1;AUD1;CAD1;NZD1;XAU1;FORECAST Correct forecasts: 58 out of 100 => 58.00%, error => 1.131192104823076
这已经足够好了,但是我们不应该忘记网络中进程的随机性:有了其他输入和其他初始化,我们会得到好的结果,甚至更糟。整个系统需要多次重新检查和重新配置。实际上,会生成多个实例,并选择最佳实例。此外,在做决定时,我们可以使用一个委员会,而不仅仅是一个网络。
统一预测
为了进行预测,不需要在屏幕上显示图形。在诸如ea或metrics的MQL程序中,我们可以使用类csom而不是csomdsplay。让我们创建一个与索引一致性预测类似的一致性,但是使用一个额外的缓冲区来显示预测。用于获取“未来”值的Kohonen网络可以单独设置(在SOM预测中),然后加载到度量中。或者我们可以在指标中“随时随地”对网络进行培训。让我们两者兼而有之。
要加载网络,我们添加输入参数netfilename。为了教授网络,我们添加与SOM预测中包含的参数组类似的参数组:cellsx、cellsy、hexagon cell、usenormalization、epochnumber、show progress和random seed。
不需要参数绝对值,所以让我们用“false”常量替换它。shiftlastbuffer没有意义,因为新的指标总是意味着预测。导出的csv文件被排除在外,所以我们删除参数savetofile。相反,我们将添加标记save trainednetworks:如果它是“真的”,那么度量将把所教的网络保存到一个文件中,这样我们就可以在som forecast中研究它们的图形。
参数barlimit将用作开始显示的列数和用于培训网络的列数。
新的参数重新传输栏允许您指定网络必须重新传输的间隔之后的列数。
让我们包含一个头文件:
#include <CSOM/CSOM.mqh>
在分时功能中,让我们检查一个新列的可用性(所有资产中的列同步都是必需的-在这个演示项目中没有完成)。如果是更改网络的时间,请从文件NetFrimeNEAM加载它,或者在函数TrimSOM中对索引数据进行教学。之后,我们将使用预测函数来预测。
if(LastBarCount != rates_total || prev_calculated != rates_total) { static int prev_training = 0; if(prev_training == 0 || prev_calculated - prev_training > RetrainingBars) { if(NetFileName != "") { if(!KohonenMap.Load(NetFileName)) { Print("图载入失败: ", NetFileName); initDone = false; return 0; } } else { TrainSOM(BarLimit); } prev_training = prev_calculated > 0 ? prev_calculated : rates_total; } ForecastBySOM(prev_calculated == 0); }
下面列出了SOSOM和预测函数(简化形式),附加到文章中的完整代码。
CSOM KohonenMap; bool TrainSOM(const int limit) { KohonenMap.Reset(); LoadPatterns(limit); KohonenMap.Init(CellsX, CellsY, HexagonalCell); KohonenMap.SetFeatureMask(KohonenMap.GetFeatureCount() - 1, 0); KohonenMap.Train(EpochNumber, UseNormalization, ShowProgress); if(SaveTrainedNetworks) { KohonenMap.Save("online-" + _Symbol + CSOM::timestamp() + ".som"); } return true; } bool ForecastBySOM(const bool anew = false) { double vector[], forecast[]; int n = workCurrencies.getSize(); ArrayResize(vector, n + 1); for(int j = 0; j < n; j++) { vector[j] = GetBuffer(j, 1); // 第一个柱是最近完成的 } vector[n] = 0; KohonenMap.GetBestMatchingFeatures(vector, forecast); buffers[n][0] = forecast[n]; if(anew) buffers[n][1] = GetBuffer(n - 1, 1); return true; }
请注意,我们实际上是在第0栏的开头预测收盘价。因此,与其他缓冲区相关,度量中的“未来”缓冲区不会移动。
这次,让我们测试预测试白银的行为,并在测试器中可视整个过程。Indicators will be“in progress”within the past 250 days(1 year)and retrained every 20 days(1 month).最后给出了带有设置的Unity-Forecast-xag.set文件。需要注意的是,资产工具包已经扩展:欧元兑美元、英镑兑美元、美元兑瑞士法郎、美元兑日元、澳元兑美元、美元兑加元、新西兰元兑美元、xauusd、xagusd,因此我们根据外汇报价和银本身以及黄金预测xag。
以下是2018年7月1日至2018年12月1日的测试结果。
5
统一预测:在元交易者5测试仪中基于外汇和黄金集群预测银价变化
在此期间,准确率达到60%。如果需要从根本上选择预测对象,准备输入参数,并对其进行长期的仔细配置,则可以得出结论,认为该方法是可行的。
注意!以“随时随地”的方式培训网络将阻止指标(以及具有相同交易品种/时间段的其他指标),这是不推荐的。实际上,这些代码应该在EA事务中执行。把它放在这里的指示器上,只是为了演示。要更新度量中的网络,可以使用助手EA按计划生成图形,并且度量将根据netfilenname中指定的名称重新加载图形。
可以考虑以下选项来提高预测质量:将外部因素添加到输入参数中,例如星期几,或者基于多个Kohonen网络或Kohonen网络和其他类型的网络实施更复杂的方法。
结论
本文讨论了Kohonen网络在解决交易者问题中的实际应用。基于神经网络的技术是一个强大而灵活的工具,它允许您处理各种数据处理方法。同时,他们需要仔细选择输入变量、历史深度和参数组合,因此他们的成功使用很大程度上取决于用户的专业知识和技能。本文中讨论的类允许您在实践中测试Kohonen网络,获得使用它们的必要经验,并将它们应用到自己的任务中。
本文由MetaQuotes Software Corp.翻译自俄语原文
,网址为https://www.mql5.com/ru/articles/5473。
MyFxtop迈投(www.myfxtop.com)-靠谱的外汇跟单社区,免费跟随高手做交易!
免责声明:本文系转载自网络,如有侵犯,请联系我们立即删除,另:本文仅代表作者个人观点,与迈投财经(www.myfxtop.cn)无关。其原创性以及文中陈述文字和内容未经本站证实,对本文以及其中全部或者部分内容、文字的真实性、完整性、及时性本站不作任何保证或承诺,请读者仅作参考,并请自行核实相关内容。
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。